Language Science Press currently offers electronic versions of published books only in PDF format. This blog post describes our plans for providing additional book formats in the near future and our recent progress.
As you might know, the required submission format for LangSci books is LaTeX (.tex). For books in Microsoft Word (.doc) or Libre Office (.odt) format, we offer a webservice to generate an initial LaTeX version. After the final editing and polishing steps, the heavy lifting to produce a PDF document from the LaTeX source is done by xelatex. So if we include the optional preprocessing stages in the picture, the current production pipeline can be represented as follows:
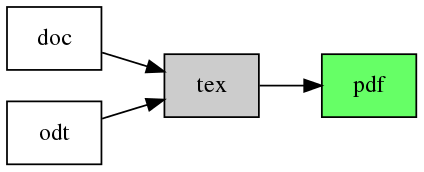
We are currently working on substituting that with the following conversion network:
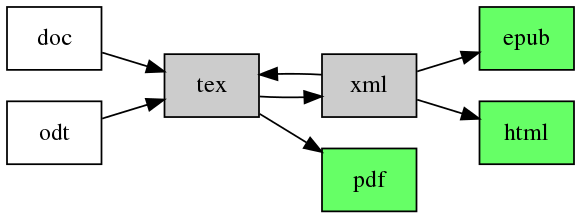
Once this is in place, Language Science Press will be able to offer every book in three main output formats:
- PDF: for a classic page-based presentation of the content that matches the printed book
- HTML: for reading in a webbrowser and for linkable content (making it easy to refer to a specific paragraph or example sentence in a LangSci book with a link)
- EPUB: for reading on an e-book reader or on other devices with appropriate apps (like iBooks, FBReader, etc.)
Additionally, there will be a structured representation of the book content in XML format. This can be used to access pieces of information in a standardized machine-readable format, e.g. to extract linguistic example sentences or syntactic tree structures. The XML format also plays an important role as an intermediate step for producing HTML and EPUB versions of the book.
We are also planning to use the HTML version of books in a pre-publication stage with Annotator as an easy way for reviewers and proofreaders to provide feedback or add comments at specific positions in the document.
While there are many existing tools to convert LaTeX documents into other formats (e.g. pandoc, plasTeX, HeVeA, tex4ht), none of them is capable of handling documents with typical linguistic content in an entirely satisfactory way. In particular, we want to make sure that glossed example sentences, syntax trees, attribute-value matrices and other data types commonly found in linguistic writing are automatically handled correctly. That’s why we are developing additional conversion tools, specifically designed to handle these cases. In particular, in the past few months we have been working on a LaTeX parser that will serve as the basis for extracting custom data structures from LangSci books, like glossed example sentences or syntactic trees. Since the parser is written in Haskell, it is easy to interface with the universal markup converter pandoc, which already provides excellent conversion routines to HTML and EPUB, among many other formats.
In principle, it would be desirable to integrate our parsing extensions directly into pandoc, but since pandoc aims to support an impressive list of input and output formats and is designed for a wide range of use cases, its internal data structures are less flexible than those of our LangSci-specific LaTeX-only reader. However, we already started to contribute code to pandoc and are planning to keep a close relationship to its development. The exact document representation for LangSci books is still in the design process, but we intend to provide a direct interface to pandoc’s internal types which would massively increase the list of input and output formats that Language Science Press could support. Still, our main focus for the next months is on a proper mapping of linguistic data structures to HTML and EPUB. As our toolchain becomes ready for general use, we will announce its availability under an open license in a future blogpost.
Some parts of this conversion pipeline are already working. For example, we have used an early version of the converter to extract XML representations of linguistic example sentences from the LangSci books published so far. These files can be accessed here.
A final note: Our conversion tools are designed for documents that adhere to the LangSci Guidelines. These guidelines do not only ensure a consistent look and feel for all LangSci books, but also help our conversion tools to make sense of the content and map it appropriately to formats like HTML and EPUB.
on behalf of Michal:
I am in tex4ht development team. Wouldn’t it be easier option than
writing custom LaTeX parser just adding configurations for linguistic
packages to tex4ht? It uses TeX to actually parse the document, so it
supports all LaTeX commands and packages, but custom configurations
are needed if one wants to add some logical markup and to fix visual
style. See
https://github.com/michal-h21/helpers4ht/wiki/tex4ht-tutorial#configurations
for some discussion. I am sure you would get some support if you ask
some question on tex4ht mailing list or issue tracker, we highly
welcome any user requests. We try to support most widely used packages
ourselves, but it is impossible for us to provide configurations for
all thousands packages on CTAN.
Hi Michal,
thanks a lot for writing! Of course, I’m aware of your excellent work on ebook generation from TeX — it’s a great contribution to the TeX world. I’m also glad to see that tex4ht is moving forward more quickly again.
We didn’t make the decision to roll our own parser lightly. I had a close look at many existing tools, including tex4ht, but none of them was ideal for our exact purposes. For instance, tex4ht seems to generate XML by directly injecting tags as string literals around TeX groups, and most of this code is written directly in TeX. But we need more flexibility in some places: When processing glossed sentences, for example, we need to apply some matrix and string operations that are cumbersome to express in TeX and would lead to code that is much harder to maintain than the corresponding one-liner in a more modern general-purpose language.
From my point of view, tex4ht is an excellent tool for general conversion from TeX, especially to HTML, but we have very specific needs in terms of the XML output format that require tools that go beyond what simple configuration files for tex4ht are likely to do.
That said, I will keep a close eye on tex4ht development, it’s a great project and it’s good to be in touch!