12065.HA.meinschäfer
1.
1. 1. draft abstract
ich werde in dieser arbeit den versuch unternehmen, ein im rahmen empirischer studien durchgeführtes psycholinguistisches experiment ausführlich zu dokumentieren. die studie, welche noch nicht beendet ist, wurde in einem forschungsseminar der bua1 in kooperation von teilnehmern von fu, tu, hu unter der aufsicht der charite durchgeführt. es handelt sich i diesem teil um die partielle replikation des von paula rubio-fernandez (#ref R/F2) unternommenen versuchs, das metaphernverständnis von schizophrenen personen zu untersuchen. dazu wurde in der kontrollgruppe ein self paced reading experiment veranstaltet und ausgewertet.
1.3. zum experiment
das experiment hat in einer laufzeit von zwei wochen daten von 46 versuchspersonen erhoben, die hauptsächlich in der statistiksprache R ausgewertet wurden. basis der daten ist die messung von lesezeiten in einem set von 24 items3, die in vierfacher ausprägung literale und figurative elemente in kurzen zusammenhängen verbanden.
1.4. theorie rahmen
Mit Carston (2010#ref carston4) sind wir davon ausgegangen, dasz im experiment zu untersuchende single (SM = Metapher eingebettet in literalen Kontext) und extended metaphors (EM = erweiterte Metapher, eingebettet in weitgehend figurativen Kontext) unterschiedlich verarbeitet werden, wobei durch die notwendige Aktivierung und Reaktivierung der literalen Bedeutung (ad hoc concept) an SM ein höherer Aufwand nötig sei#ref, der im Gegensatz zu EM in einer längeren Lesezeit resultiert. Diese Annahme führt zu folgenden Fragestellungen, die in Anlehnung an ein Experiment (Verifikation/Replikation) von Paula Rubio-Fernandez et al. (2016#ref) hier aufgenommen wurden:
- unterscheiden sich die Lesezeiten kurzer Texte, die nach den Annahmen folgendem Muster single und extended metphors enthalten oder rein literal (LC) aufgebaut sind?
- wie unterscheidet sich eine vierte Variante, bei der die Struktur der SM invertiert wurde (ISM = literales Element eingebettet in weitgehend figurativen Kontext), hinsichtlich ihrer Verarbeitungszeit?
Die zu überprüfenden Hypothesen lauten wie folgt:
- Lesezeit SM > Lesezeit EM
- Lesezeit EM = Lesezeit LC
- Lesezeit ISM = SM > EM = LC
Zur Überprüfung der Hypothesen wurde das self paced reading Experiment durchgeführt, das die Lesezeit in den unterschiedlichen Kategorien erfasste.
2. R/F, carstons, metaphern, konkretismus
3. dokumentation
3.1.
ich werde im folgenden den aufbau und ablauf des experiments erklären und im nächsten kapitel dessen hypothesengeleitete auswertung erläutern.
3.1.1.
die versuchspersonen bekamen während des tests, der online über einen link abrufbar war, ein set aus jeweils 8 items (kontexte) die wiederum die varianten der variable ?einbettung der metapher? in ausprägungen von
- LC (metapher literal in literalem kontext)
- SM (metapher figurativ in literalem kontext)
- EM (metapher figurativ in figurativem kontext)
- ISM (metapher literal in figurativem kontext)
enthielten sowie einen bestand aus 16 filler items, die sich ebenfalls in den kontextvarianten unterschieden. die proband/ lasen einen text, von dem jeweils nur eine zeile nicht maskiert war, die jeweils folgende zeile wurde durch das drücken der leertaste sichtbar. so konnte die verweildauer auf einer sichtbaren zeile gemessen werden. als grundlage für die messung wurde ein von (JESPR#ref5) frei verfügbares javascript benutzt, das an unsere bedürfnisse angepasst worden war; u.a. war ursprünglich keine dauerhafte speicherung der daten in einer datei vorgesehen, diese funktion wurde von mir mit einigem aufwand realisiert, so dasz die lesezeiten danach in einer tabelle verfügbar waren. die einbettung des experiments in einen auf der platform soscisurvey.de als akademische studie angemeldeten fragebogen erforderte ebenfalls einigen aufwand, da die randomisierung der itemabfrage in anderer weise als vom script vorgesehen geschehen muszte. die daten selbst enthielten werte für:
- den start und endpunkt des durchgeführten tests (tnid)
- die position der einzelnen maskierten phrasen im satz (targetposition) (unabhängige variable)
- die verweildauer auf den jeweiligen positionen (elapsed time) (abhängige variable)
- angaben über die zuordnung der phrasen zur jeweiligen ausprägung (kategorie) der unabhängigen variablen
3.1.1.1 zum inhalt des tests
die items, die in anlehnung an R/F nach obigem muster von uns entworfen wurden, entsprachen im aufbau dem set, das R/F in ihrem test verwendet hatte; vier ihrer im anhang (#ref) zur verfügung gestellten items hatten wir ins deutsche übersetzt und eines davon als item in vier varianten, die restlichen als filler übernommen. die auswahl der verwendeten items wurde gemeinschaftlich nach kriterien wie konsistenz innerhalb der items, stil und kohärenz bestimmt. ebenfalls nach den constraints von R/F gerichtete vorgaben wie wort- und satzlänge, itemlänge und position des targets hatten beim entwurf eine wichtige rolle gespielt, waren jedoch nicht immer optimal umgesetzt worden; dazu einige bemerkungen im auswertungsteil.
ein item sollte eine metapher in je figurativer und literaler bedeutung, eingebettet in einen je figurativen oder literalen kontext, d.h. also in insgesamt vier unterschiedlichen konfigurationen, präsentieren. die metapher (unser target) sollte sich im dritten viertel des kontextes befinden, um davor und danach auftretende latenzen der lesezeit auswerten zu können. dafür wurden im script des tests die positionen der einzeln zu lesenden phrasen des items mit 0 für das target und je negativen und positiven werten für den abstand zum target festgelegt.6
das set eines einzelnen durch abruf des fragebogens aufgerufenen tests bestand für jede/ studienteilnehmer/ aus einer randomisierten auswahl einer von vier mal acht itemvarianten (aus der menge von 8 items), womit jeweils zweifach meszdaten der vier varianten pro tn erhoben werden konnten, aber niemals ein tn ein item in mehreren varianten las. die 16 filleritems traten innerhalb des sets aus also 24 items an einer zufälligen positionen auf, wurden aber bei allen tn aus demselben pool bedient und wiesen ausgeglichene variation hinsichtlich der figurativ-literalen konfiguration auf.
4.auswertung
4.1.
o.a. daten wurden in R(#ref7) 1. deskriptiv und 2. mittels des paketes lme48 zur erhebung kovariater abhängigkeiten (linear mixed model) analog der vorgaben RF#ref ausgewertet. das script dazu kann hier evaluation, sowie eine erste vom user in einzelnen parametern veränderbare auswertung hier nachvollzogen werden.
4.1.1.
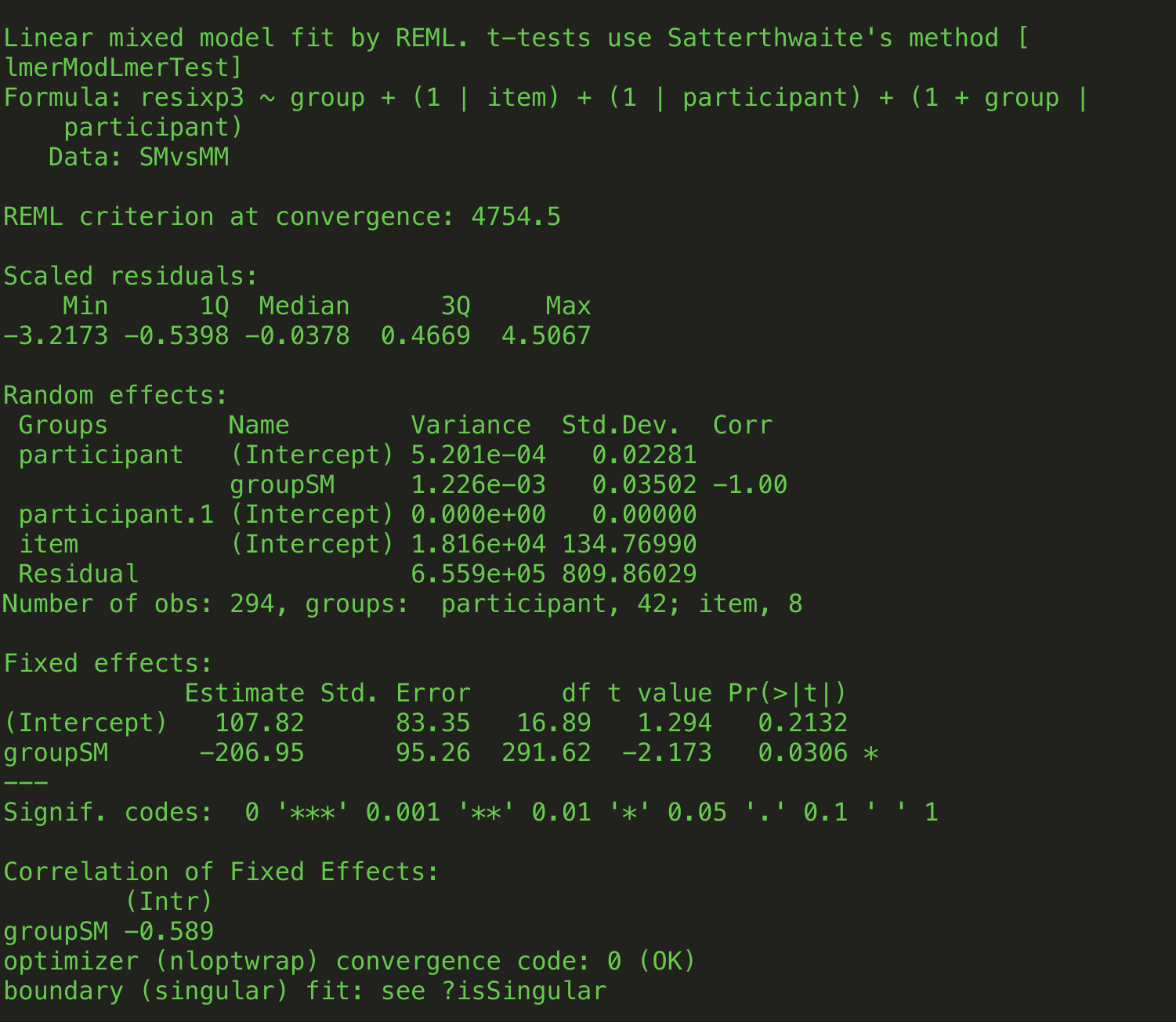
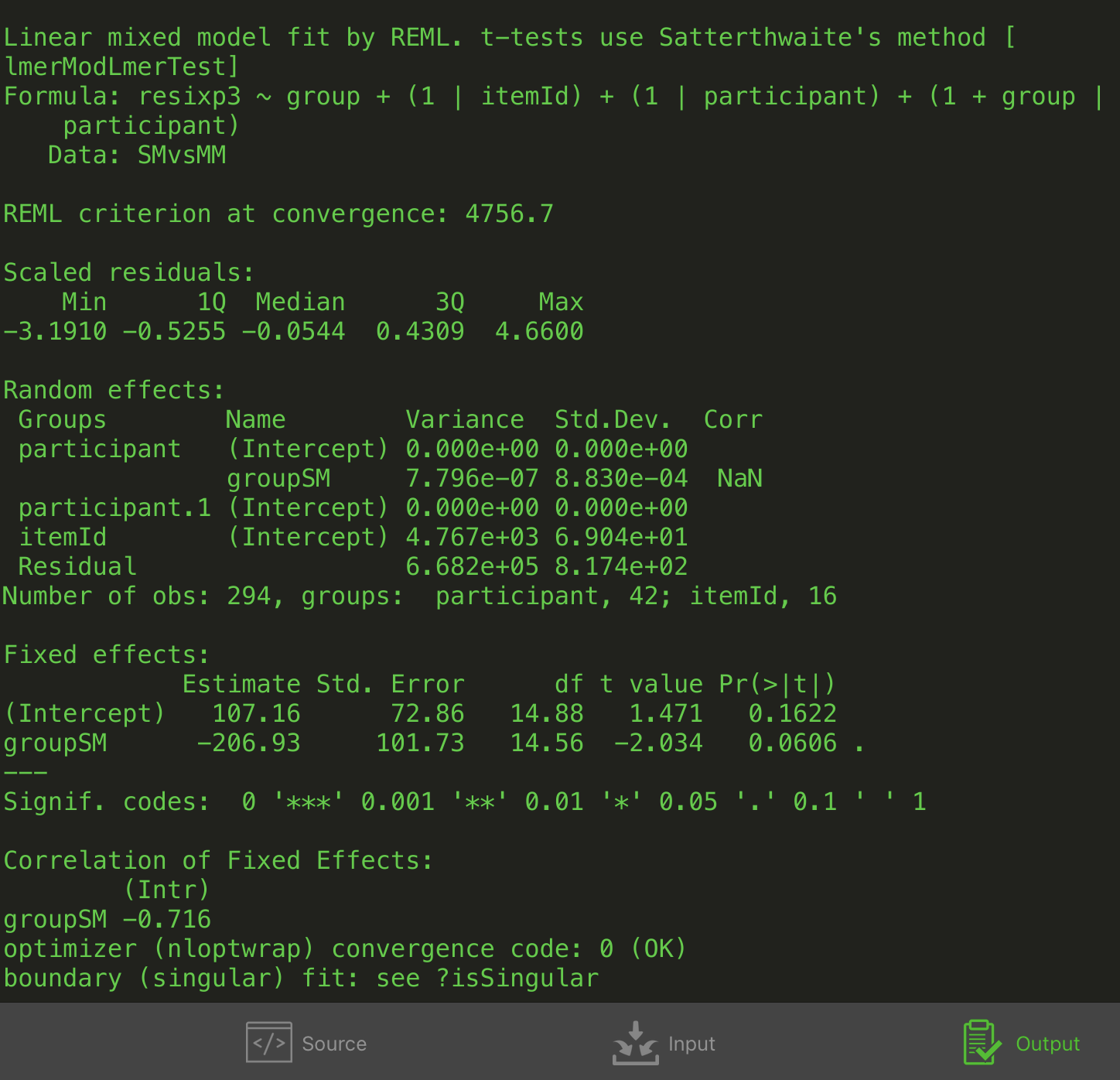
zur auswertung wurde die auf einem server durch ein php-script im flachen comma seperated format gespeicherte tabelle in R importiert. um zu gewährleisten, dasz abweichungen hinsichtlich der zeichenanzahl der zeitgemessenen phrasen keine unerwünschten effekte in der berechnung der latenzen zeitigen, wurde bei jeder weiteren berechnung dafür ein von der zeichenanzahl/phrase anhängiger koeffizient einbezogen, der in der ersten, deskriptiven auswertung einfach aus der zeichenanzahl, bei der zweiten kovariaten auswertung mittels lme4 bestimmt (Fine al. 2013,#ref 9) und als residual, hier: korrigierte lesezeit, einbezogen wurde.
deskriptiv konnten am target keine signifikanten unterschiede in der durchschnittlichen lesezeit festgestellt werden. r/f jedoch hatte ihre daten mit dem r-paket lme4 unter multivariaten gesichtspunkten analysiert. so konnte auch ich (in dieser phase ging die experiment arbeitsgruppe getrennte wege) nach feststellung des effekts der phrasenlänge und berücksichtigung desselben als korrigierte lesezeit, hier: die abhängige variable in der lmer formel, signifikante unterschiede der lesezeiten von ISM und LC feststellen. allerdings nur an dieser stelle, womit einzelne hypothesen nicht bestätigt werden konnten. bei der multivarianzanalyse wurden hier ein main effect der kategorie (lc,sm,em,ism) (group) unter random effects von tn (participant) und kategorie auf tn (group by participant) betrachtet.
- berlin university alliance ↩︎
- Paula Rubio-Fernández, Chris Cummins, Ye Tian. Are single and extended metaphors processed differently? A test of two Relevance-Theoretic accounts. Journal of Pragmatics, Volume 94, 2016, Pages 15-28, ISSN 0378-2166, (https://doi.org/10.1016/j.pragma.2016.01.005). (https://www.sciencedirect.com/science/article/pii/S0378216616000060). ↩︎
- item hier als ein in vier ausprägungen entworfener text mit durchschnittlicher länge von 400 zeichen. ↩︎
- Carston, Robyn, 2010. XIII—Metaphor: Ad Hoc Concepts, Literal Meaning and Mental Images. Proc. Aristot. Soc. 110, 295–321 (Blackwell Publishing Ltd.). ↩︎
- Rose, L. Ralph, 2016. JESPR: self paced reading experiment. MIT license. (https://github.com/fildpauz/jespr). ↩︎
- da diese positionen wegen nachlässigeit erst :nach: start des tests konsequent im script festgelegt wurden, muszte bei der auswertung einiges manuell nachgearbeitet werden, um die daten konsistent zu halten. ↩︎
- R version 4.1.0 (2021-05-18) — „Camp Pontanezen“ Copyright (C) 2021 The R Foundation for Statistical Computing. (https://www.rstudio.com/products/rstudio/). ↩︎
- Bates et alii, 2014. lme4: Linear Mixed-Effects Models using ‚Eigen‘ and S4. Version 1.1-27.1 (https://cran.r-project.org/web/packages/lme4). ↩︎
- Fine, A. B., Jaeger, T. F., Farmer, T. A., & Qian, T. (2013). Rapid Expectation Adaptation during Syntactic Comprehension. PloS One, 8(10), e77661–e77661. (https://doi.org/10.1371/journal.pone.0077661) ↩︎