We have recently published two dictionaries in our series African Language Grammars and Dictionaries which were automatically converted from the FLEX lexical database. These two books are The Ik language and A dictionary and grammatical outline of Chakali.


In this post, I will detail how structured lexical data as found in FLEX can be converted to *tex, which can be compiled into a LangSci book. I will complement this with some observations about conversions from the XLingPaper format.
Elsewhere, I have described the conversion of MS Word/LibreOffice documents to LaTeX. These two formats contain running text, which has generally low degree of structuredness. This is different from dictionaries, where the content is highly structured, and the very same elements of headword, part-of-speech, gloss and some other elements repeat over and over again.
This is why dictionaries are often prepared not in general text processors, but in specialized programs, such as the Fieldworks Language Explorer, FLEx for short. Ideally, such programs have a variety of export functions, which allow the transfer of the information to another program. I have not worked with FLEx myself and I cannot tell you whether it is good for collecting and organising data, but it has at least two different export formats which are suitable for my goals: XML and LIFT.
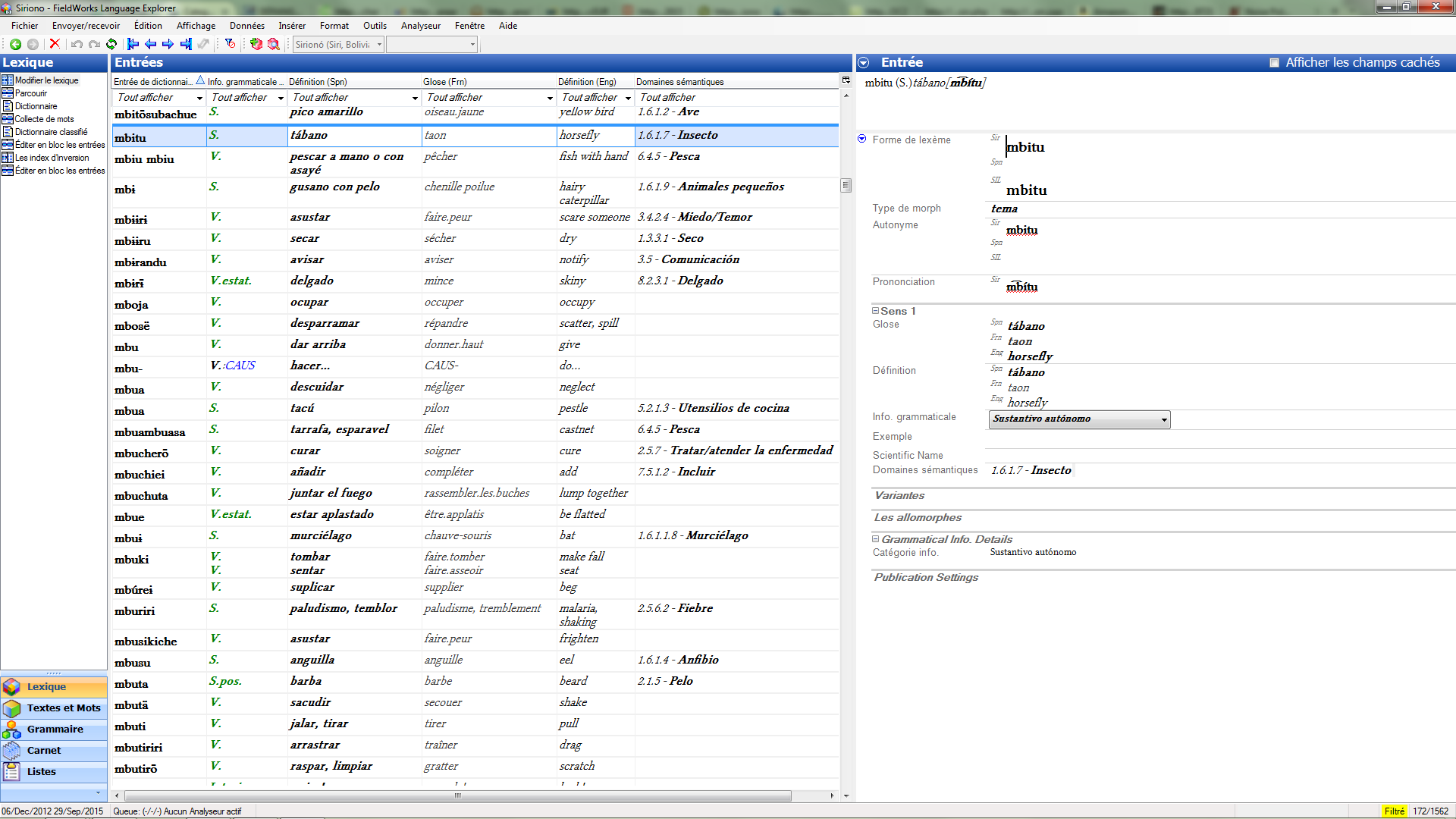
The Fieldworks Language Explorer interface. https://commons.wikimedia.org/wiki/File:SIL_Fieldworks_Language_Explorer.png CC-BY-SA https://commons.wikimedia.org/wiki/User:No%C3%A9
Case study I: Chakali
The Chakali project started in April 2014. The author, Jonathan Brindle, wrote
I was wondering how LSP plans to deal with dictionaries in Latex; will you provide with a stylesheet capable of transforming a non-tex file e.g. LIFT-XML (this is my case) into smth latex-compilable?
I took this as an occasion to look at the FLEx output formats and opted for the XML output. The idea was to take an XML tag like <LexEntry_HeadWord> and convert it into a corresponding tex command (\headword). At first I tried to do a completely agnostic mapping of XML to tex commands, but I soon had to discover that some additional analysis of the tags was necessary, as some relevant information was hidden in XML attributes for instance. Below you find an excerpt of the FLEx XML output and the result of the conversion to tex.
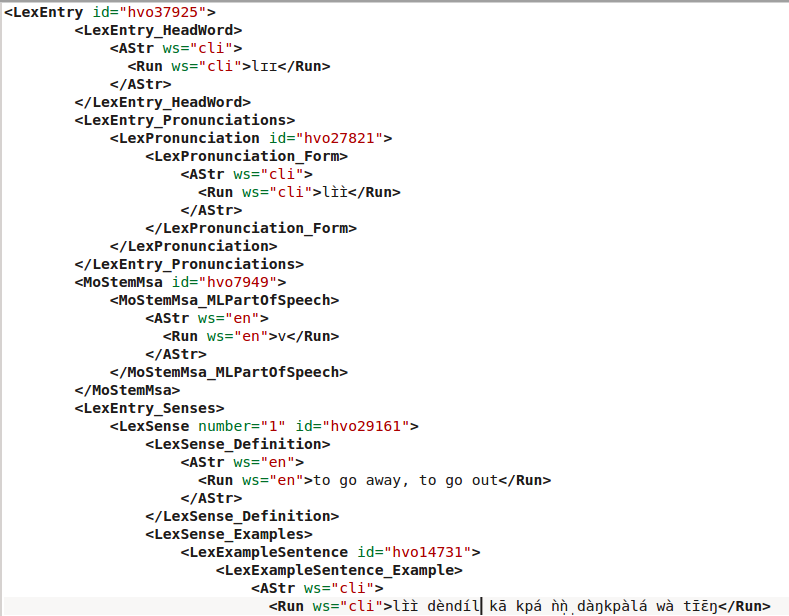
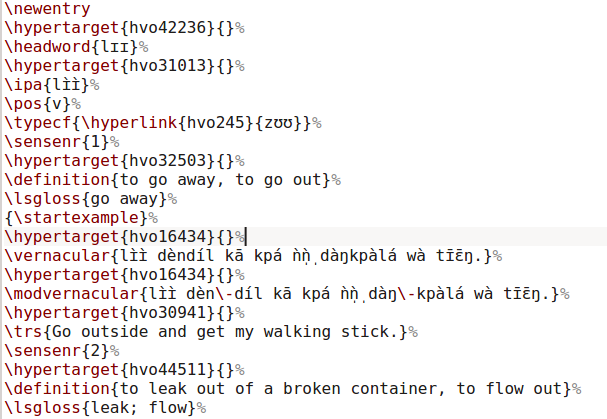
This is the tex code for one entry. When compiled into pdf (providing the necessary formatting commands for the relevant elements), this renders as follows: The particular challenge in this case was to preserve the links between variants and synonyms (that’s the
The particular challenge in this case was to preserve the links between variants and synonyms (that’s the hypertarget fields). Other challenges included some inconsistencies in the XML structure, and automatic hyphenation of the entries, in particular syllabification of entries with prenasalized stops or labiovelars.
The conversion was complemented by the automatic generation of a reversal/lookup index. This was straightforward with the only complication being the addition of sense numbers where they were needed for disambiguation.
 As a special feature, the headword used in the reversal index could be changed. This can be seen in the
As a special feature, the headword used in the reversal index could be changed. This can be seen in the *tex excerpt above, where the definiton “To leak out of a broken container” is included in the dictionary, but only “leak” will be included in the reversal index.
Case study II: Ik
For the Ik dictionary, the same general setup was used, but this time with the LIFT export rather than the XML export. This proved much easier to process. The following three images show the relevant parts of the XML file, the tex file and the resulting pdf. Note that the LIFT format is much less deeply nested than the FLEX-XML export
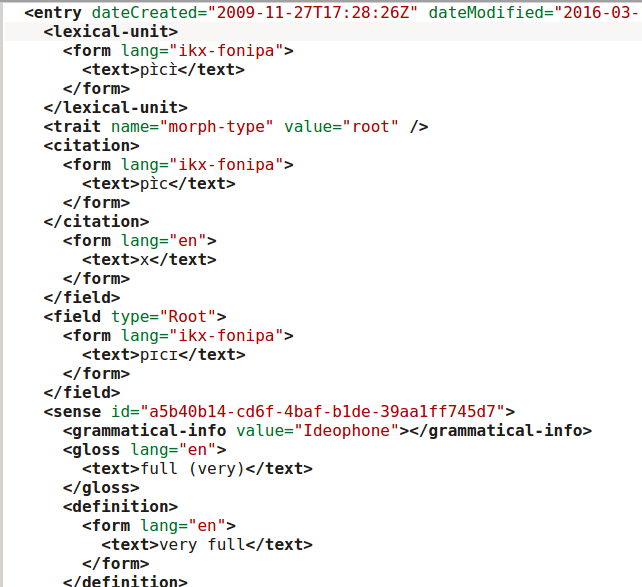
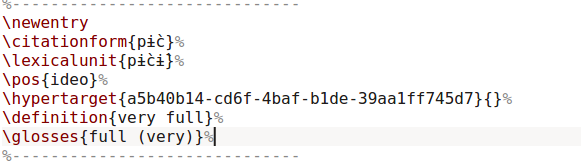
 The reversal index was done in the same way as for Chakali, reusing the same script, but with
The reversal index was done in the same way as for Chakali, reusing the same script, but with citationform instead of headword and generally less detailed information.

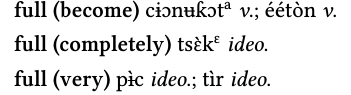 For Ik, some expert knowledge was necessary to get the hyphenation right and to adjust the alphabetical ordering of vowels with regard to [±ATR] and diacritics. Other than that, much of the original setup could be reused. One major drawback of the LIFT format, however, is that the links between synonyms are not preserved. This was not a big problem in this case since that information was included as literal “see also” in the field
For Ik, some expert knowledge was necessary to get the hyphenation right and to adjust the alphabetical ordering of vowels with regard to [±ATR] and diacritics. Other than that, much of the original setup could be reused. One major drawback of the LIFT format, however, is that the links between synonyms are not preserved. This was not a big problem in this case since that information was included as literal “see also” in the field note anyway.
To sum up, the LIFT format proved to be more consistent and more straightforward in its structure. Both factors contributed to this format being even easier to convert than the FLEX-XML export. This comes at a cost, though: links between different entries are not preserved.
XLingPaper
In a somewhat related vein, we recently experimented with conversions of papers written in XLingPaper format. XLingPaper allows to write papers or books with some provisions for the insertion of particular linguistic content. We have been approached by a team of researchers who use XLingPaper for their book output; at least six books are planned. Again, I have no experience with writing in XLingPaper; I only look at the export formats provided.

Screenshot of XLingPaper from https://software.sil.org/downloads/r/xlingpaper/resources/documentation/UserDocXMLmind.htm
We did a first try with a sample chapter. It took about one day to write a converter to cover all the relevant structural information contained within that chapter and translate it to tex commands used in our LaTeX templates.
Since this worked out fine, we tried the converter with an existing 500 page book written in XLingPaper, Kris Ebarb’s Tone and Variation in Idakho and Other Luhya Varieties. This took another day. There were some additional fields to take care of in the larger document, which is not very surprising, but also some attributes which were named and used differently, which is more problematic for scalability if this variation persists across documents. Still, I am confident that conversion of XLingPaper documents to LangSci LaTeX templates should be relatively straightforward, more so than, say, conversion of MS Word or LibreOffice.
Below you find the pdf generated from the original XLingPaper via the XLingPaper pdf export, followed by a pdf generated after the conversion from XLingPaper XML to LangSci tex. Note that the page numbers are slightly different (due to different line spacing), as are the example numbers. But since crossrefs are automatic, this does not really matter: (118) becomes (88), and the crossref just below is updated to (88) as well. Also note that some postprocessing will still be necessary. In this particular case, the right hand column should not be in italics, and the subscripts are slightly off. But those issues are relatively easy to fix.
Also note that the converted document has full sectioning in the left pane, while the original only has it up to the second level, e.g. 2.4.

PDF generated directly from XLingPaper

PDF generated with the LangSci LaTeX class after converting XLingPaper XML to *tex
Outlook
All converters are freely available from https://github.com/langsci/conversion/tree/master/flex and https://github.com/langsci/conversion/tree/master/xlingpaper. They will be updated as new documents to be converted come in. If there is enough demand, we will set up an online converter where you can upload your XLingPaper, convert it to *tex and directly forward it to Overleaf, similar to our docx/odt converter.
Very interesting work! I’ve been trying to come up with similar workflows in completely different end of the lexical database building; most of the lexicons I deal with are built within computational linguistics typically with a specific application in mind, especially within the framework of finite-state morphology (i.e. originally of Xerox lexc etc., nowadays more like hfst / apertium in the open source side). I have only been introduced to flex/toolbox-style work recently. In the end of course both workflows will result in a high-coverage lexical databases with lot of data about lexical entries. It would be interesting to try on some spare-time vacation if there exists some round-trippable conversions between these systems