We started our annual retrospectives in 2015 (2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024) This is the eleventh installment, for 2025.
Books and series
In 2025, we published 39 books:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
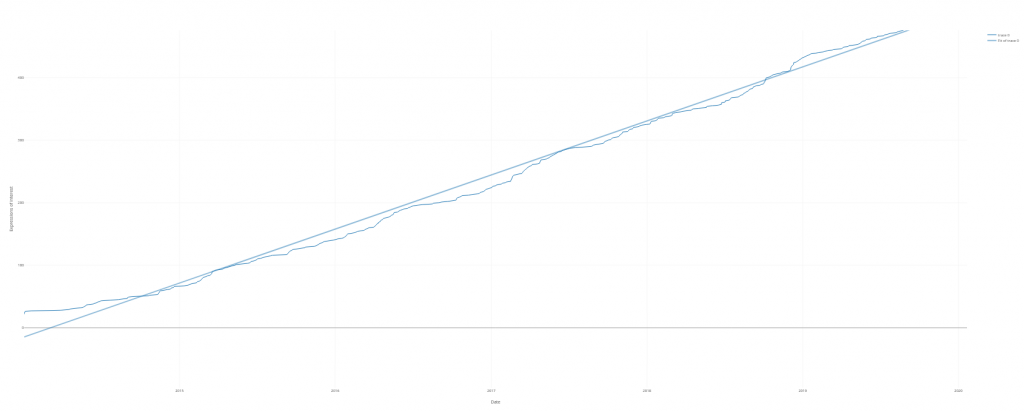
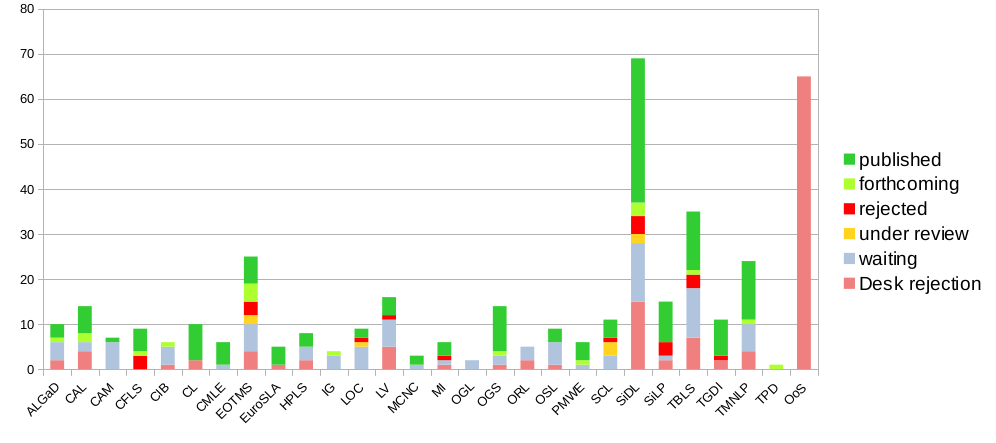
124 works were proposed to Language Science Press in 2025, for a grand total of 1099 since 2014. In 2023, 95 works had been proposed.
The following figure gives a breakdown of the distribution of these works and their states of completion:
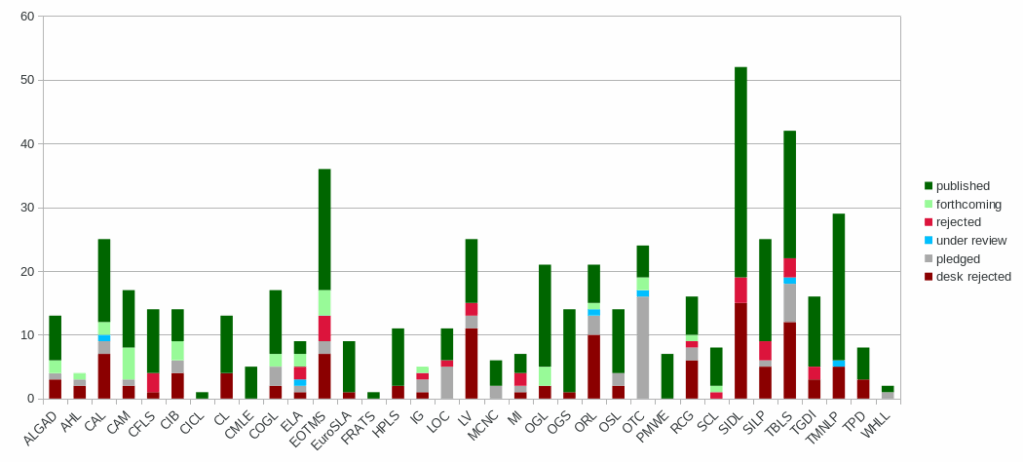
Series
There are currently 37 series (+1). In 2025, we accepted Spoken Language Research as a new series.
Reviewing
The median time from submission to decision is still 75 days. The median time from submission to publication was 339 days (-6).
The acceptance rate (counting desk rejections) is 57.88% (+0.9) over all series. Only considering submissions where the manuscript had gone into peer review, the acceptance rate is 92.10% (+0.51).
Downloads
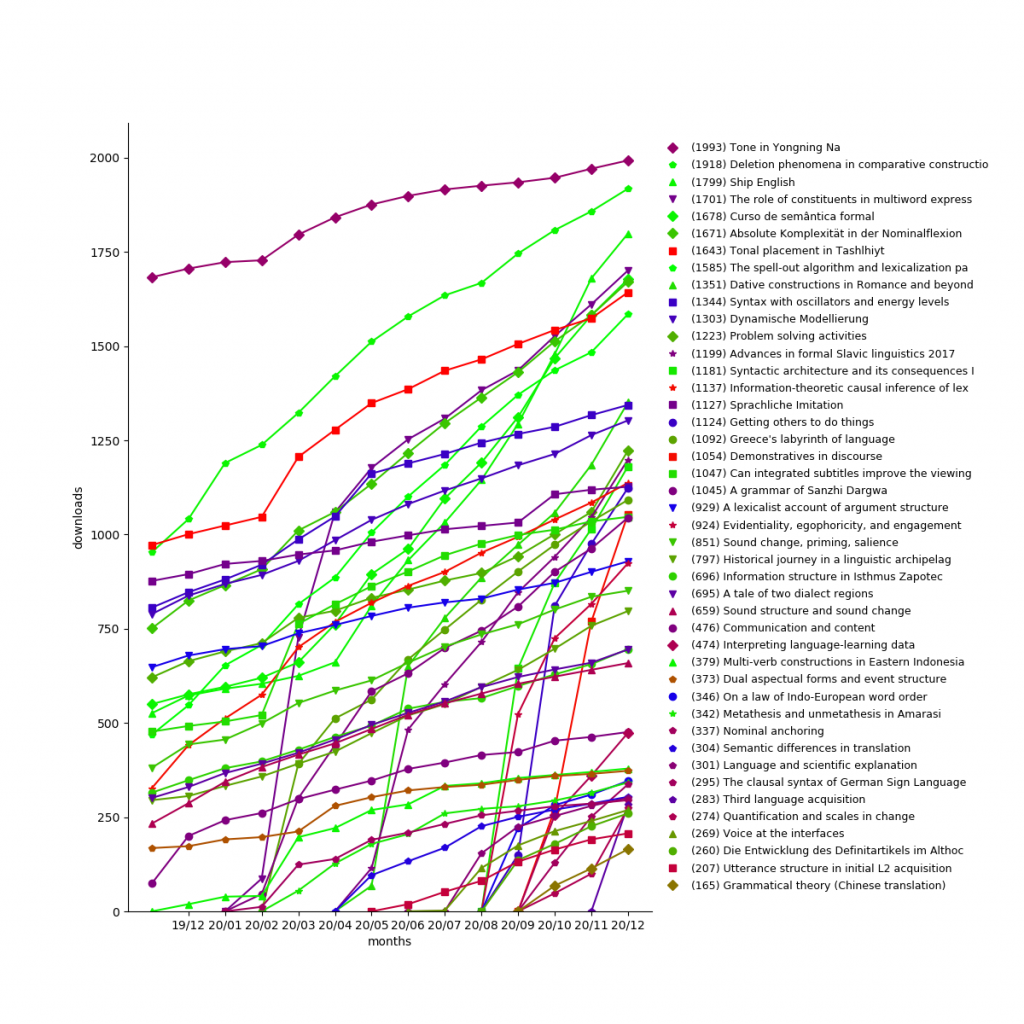
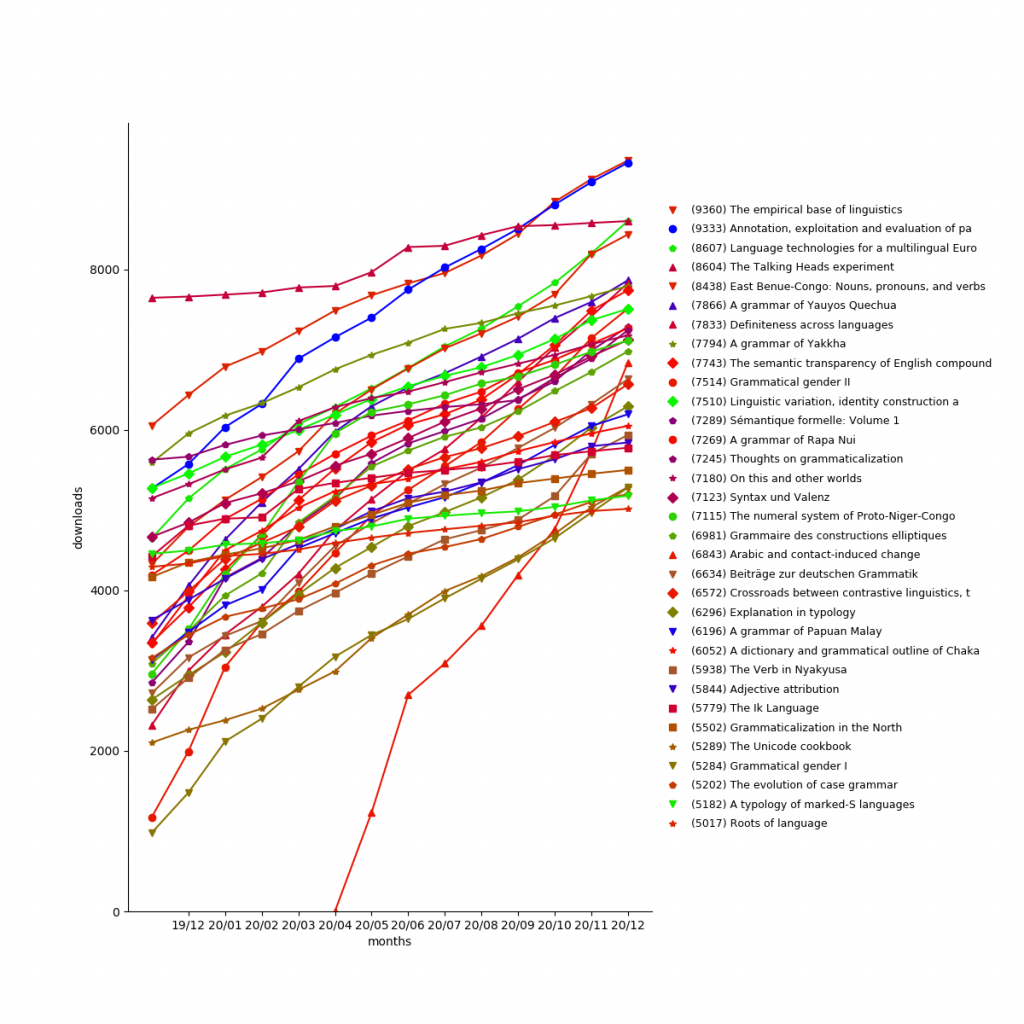
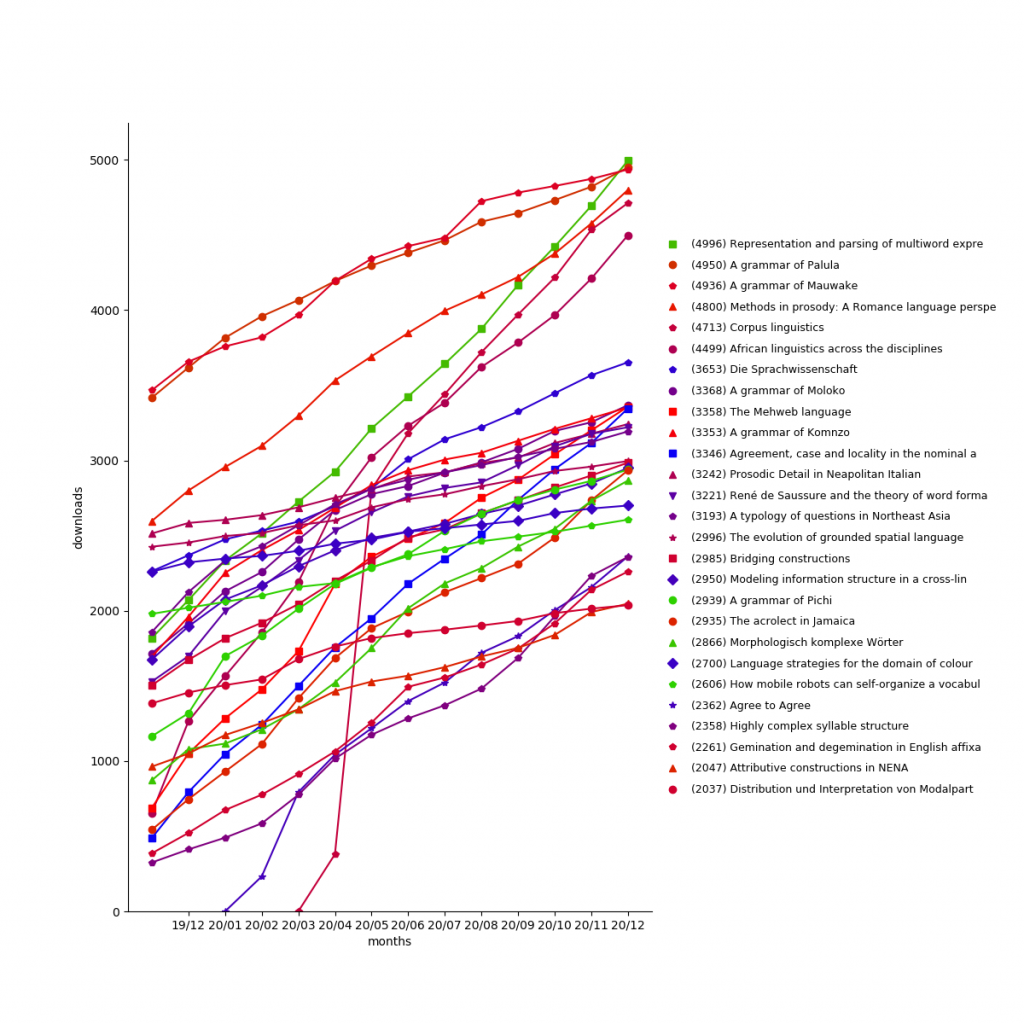
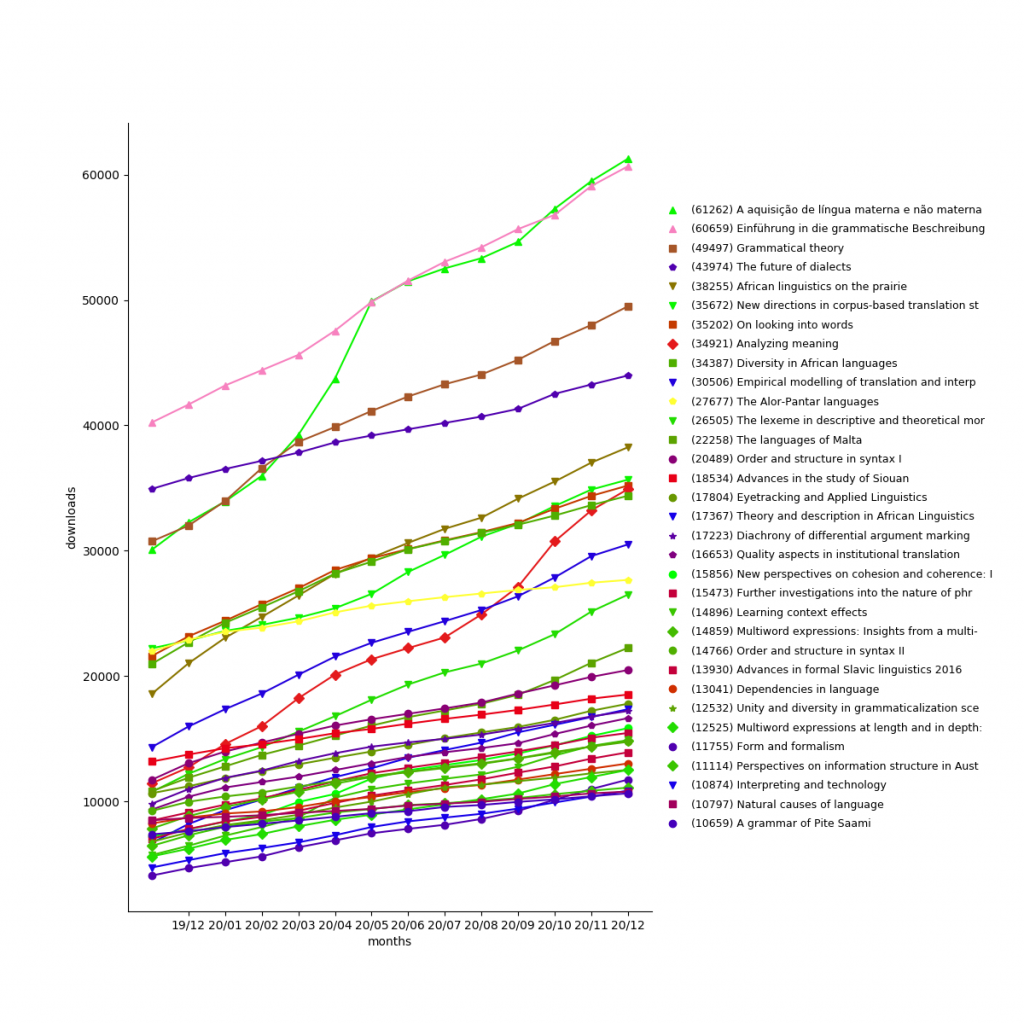
In 2025, LangSci pdfs were downloaded 656,276 times (+294,518 compared to 361,758 in 2024), for a grand total of 3,365,771.
This excludes downloads by search engine robots.
The most popular work is A aquisição da língua materna e não materna with 106,912 downloads, followed by Grammatical theory (all four editions) with 102,361 downloads and Einführung in die grammatische Beschreibung des Deutschen (all three editions) with 100,527 downloads.
Considering only the year 2025, the most downloaded books were:
- Arabic and contact-induced change: 23,566 downloads
- On looking into words (and beyond): 14,314 downloads
- A history of English: 14,156 downloads
Community involvement
Language Science Press is a community enterprise. We rely on the community for authoring and reviewing, but also for typesetting and proofreading. Across all published books, 314 linguists from all over the world have participated in proofreading. The most prolific proofreader is Jeroen van de Weijer, who has proofread chapters of 172 books.
There are currently 652 proofreaders registered with Language Science Press (+73).
For our 37 series, we are happy to be able to rely on 531 members in editorial boards from 57 different countries on 6 continents.
Paperhive
Of the books published in 2025, 30 went through proofreading on Paperhive. A total of 21,445 comments were left, for an average of 714.83 per book, or 1.89 comments per page. The book with the most comments was West meets East: Papers in historical lexicography and lexicology from across the globe (1,319). The total number of books which have completed proofreading on Paperhive is 259. Total number of comments over all books is 189,643 (mean: 734.4, median: 661, 1.98 comments/page).
CO₂
We traveled to conferences in Mainz, Herrsching, Bordeaux, Berlin, Potsdam, Mannheim, Leipzig, Stuttgart (all by train, all renewable energy).
Finances
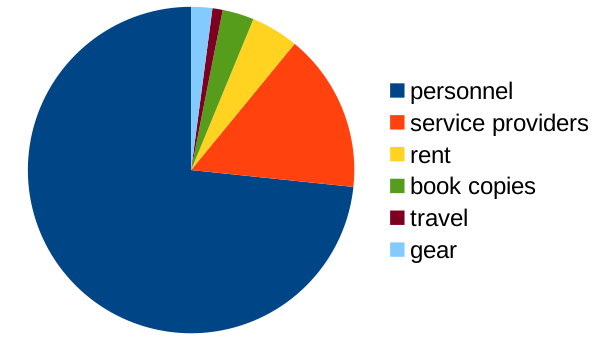
We had a revenue of 153,223.04 € (+ 7,522.91 €) in 2025 and expenditures of 143,870.24 € (+2,417.81 €). The main cost items are personnel (113,829.25 €), service providers (7,417.49 €), rent (11,066.43 €), travel (4,613.35 €), and book copies (4,730.22 €). There were seven employees with three different nationalities.
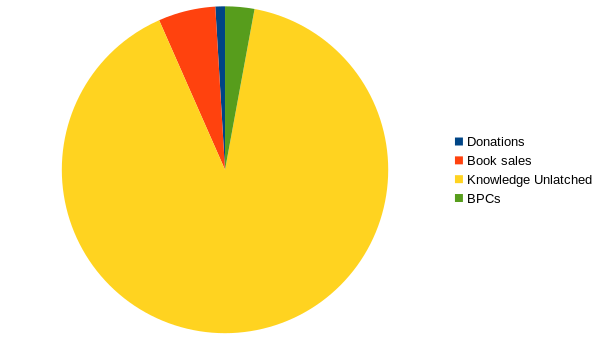
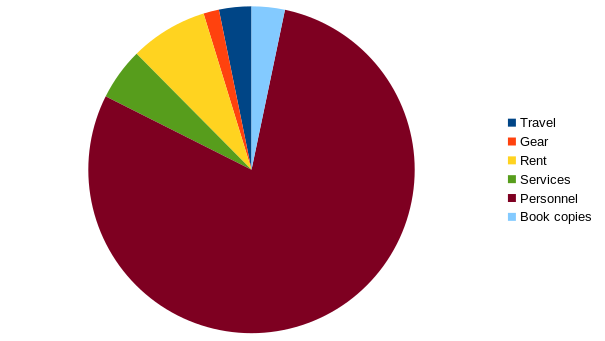
Our costs are a bit higher than last year, but the number of books published has risen as well. This leads to the average price per book going down 3,688.98 € (-134.06 €).
The lion’s share of our revenue comes from institutional memberships via Knowledge Unlatched (138,645.00 €). 8679,85 € come from print margins (-579,76 €), the rest is from diverse sources.
Note that none of theses figures include VAT.