 We are happy to announce the publication of The Unicode Cookbook for linguists: Managing writing systems using orthography profiles by Steven Moran and Michael Cysouw. Next to being a very insightful and valuable book for all linguists dealing with character encoding issues (most if not all linguists?), this publication also points the way forward in a number of domains central for the future of academic publishing in linguistics. This blog post discusses the different innovative aspects we see manifest in this book.
We are happy to announce the publication of The Unicode Cookbook for linguists: Managing writing systems using orthography profiles by Steven Moran and Michael Cysouw. Next to being a very insightful and valuable book for all linguists dealing with character encoding issues (most if not all linguists?), this publication also points the way forward in a number of domains central for the future of academic publishing in linguistics. This blog post discusses the different innovative aspects we see manifest in this book.
Multiple authors
The book has not one, but two authors. Both have contributed their respective perspectives and expertises. While we see multiple editors for edited volumes on a regular basis, multiple authors for a monograph are much less common. This has certainly to do with the fact that a monograph is much less amenable to “chunking” than an edited volume. In order to make sure that the authors do not interfere with each other’s work, a clear separation of tasks is necessary, as is version control.
Version control
The LaTeX source code of the project is available on GitHub at https://github.com/unicode-cookbook/cookbook. The authors started on 2015-03-29 with this version. All historical files are still available.
Until today, 310 updates have been made to the book, of which 174 by Moran and 121 by Cysouw. The full history of the project can be seen at https://github.com/unicode-cookbook/cookbook/commits/master. In order to have clearly designated versions for reference, the authors have created releases.
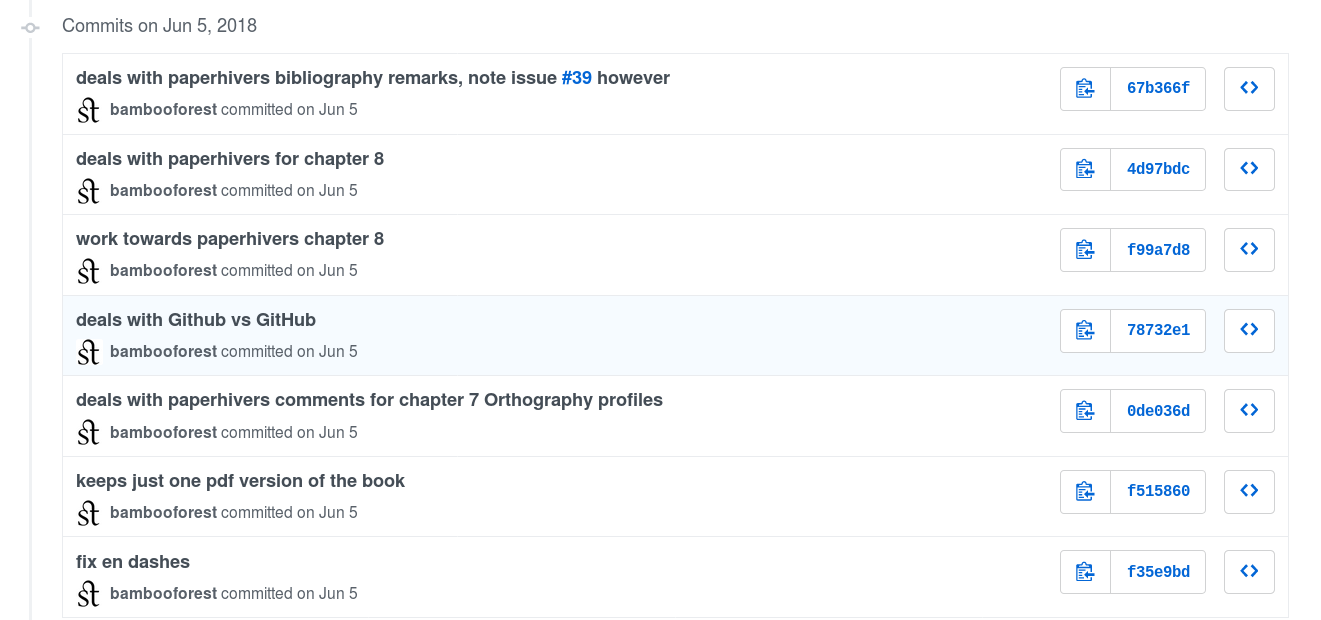
Some commits (updates) by Moran (bambooforest) from 2018-06-05 with messages describing what has been done. The full version history of the book is available on GitHub.
Archiving
This book is automatically archived on Zenodo every time a new release is made. Each release receives a new DOI (Digital Object Identifier).
When a further edition is produced, it will get its own GitHub release and it will be made available on Zenodo for archiving purposes.
Issue tracking
The finalization of this book was managed with an issue tracker. Each issue describes one clearly identified task which has to be completed before the book can be published. For instance, we have the task “Tamil not displaying correctly”. The list of all tasks is found here. When that list has length 0, the book is ready for publication. Tasks can be assigned to contributors and can be given deadlines in order to manage the completion of the project.
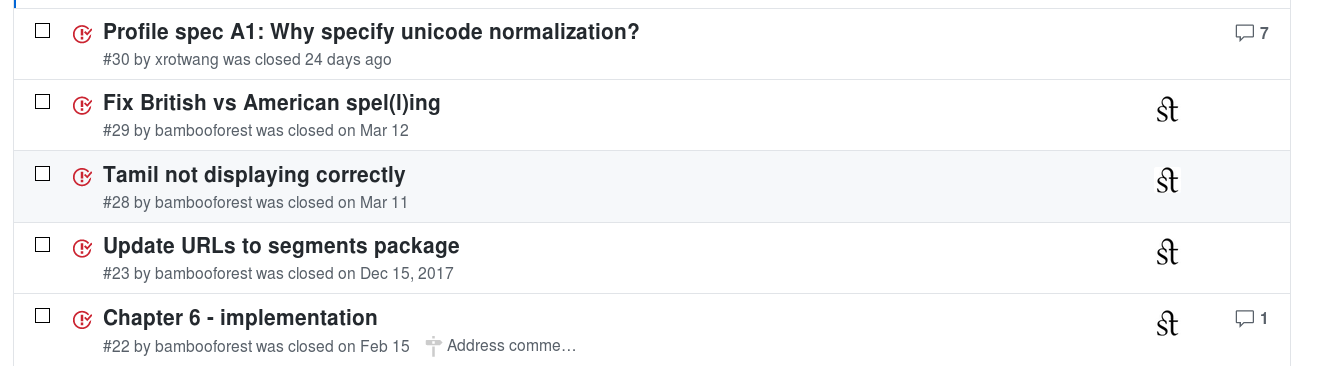
Issue list with an issue relating to the rendering of Tamil script from 2018-03-11.
Open review
 The book has been reviewed by two referees. Both reviews are signed and are available for inspection together with the book from http://langsci-press.org/catalog/book/176. This gives credit to the reviewers and also puts readers in a position to evaluate whether the quality of the book was evaluated carefully before publication. In combination with the version history and the list of issues in the issue tracker, the reviewers can see the progress of the manuscript. For instance, reviewer Robert Forkel has commented on a particular detail of the wording here: https://github.com/unicode-cookbook/cookbook/issues/30. User HughP (not a reviewer) chimed in later and also offered some comments. The open format of producing the book, combined with the clearly stated message that comments are welcome, led to reader feedback even before the book was published!
The book has been reviewed by two referees. Both reviews are signed and are available for inspection together with the book from http://langsci-press.org/catalog/book/176. This gives credit to the reviewers and also puts readers in a position to evaluate whether the quality of the book was evaluated carefully before publication. In combination with the version history and the list of issues in the issue tracker, the reviewers can see the progress of the manuscript. For instance, reviewer Robert Forkel has commented on a particular detail of the wording here: https://github.com/unicode-cookbook/cookbook/issues/30. User HughP (not a reviewer) chimed in later and also offered some comments. The open format of producing the book, combined with the clearly stated message that comments are welcome, led to reader feedback even before the book was published!
Community proofreading
HughP actually came to the book via community proofreading. We had announced the book to our list of community proofreaders on 2018-04-16. 23 linguists volunteered to read one or more chapters of the book. Most used the PaperHive platform for commenting and left 566 comments altogether. Both the comments and the historical version are still available for inspection.

Discussions on the PaperHive platform
Collaborative reading
The published version of the book is available at https://paperhive.org/documents/items/sBnRxGEsMluw for collaborative reading. This means that readers can mark passages they do not understand or find questionable and leave a comment. Other readers can then reply to these comments, offering clarification or further information.
Supplementary code
The book comes together with computer packages which illustrate the concept of orthography profiles. These are available for download from https://github.com/unicode-cookbook/recipes.
Conclusion
This book is kind of a model publication for open and collaborative publishing as it gets a check mark on really every aspect of openness on our list, from open and versioned source code to open reviews. So, what do the authors think? Steven Moran is tech lead on the ERC-funded ACQDIV project (PI Sabine Stoll) in the Department of Comparative Linguistics at the University of Zurich.
So, Steven, when did you decide to write this cookbook, and why?
Moran: The Unicode Cookbook has a long history. It was in the early 2000s, when I worked at The Linguist List, that I first encountered the technological issues involved with character encodings and linguistics data. I was part of a team tasked with developing so-called best practice recommendations for archiving endangered languages data as part of the National Science Foundation funded E-MELD project (PIs Helen Aristar-Dry and Anthony Aristar).
This work gave me the foundation that I later needed to develop a Unicode Standard compliant database of phonological inventories. During the development of PHOIBLE as part of my PhD dissertation (Moran, 2012), I encountered the many common, but not so transparent, “pitfalls” that appear at the intersection between the Unicode Standard and the International Phonetic Alphabet — specifically when trying to electronically encode the more than 3000 different contrastive phonemes reported in grammars of the world’s languages. Parts of my dissertation became the basis for the Unicode Cookbook.
It was during my work on the European Research Council funded project (2010-2014), Quantitative Language Comparison (PI Michael Cysouw), that we encountered the complex challenge of making lexical data from hundreds of document-specific orthographies interoperable and comparable for quantitative analysis. Cysouw and I developed the technological specification for orthography profiles and the software tools to work with them.
During the project, we documented the various pitfalls that we encountered when working with the Unicode Standard. At first we planned to write and submit an academic paper, so that we could share these experiences with other language scientists. However, the paper became longer and longer, so we opted for writing the Unicode Cookbook.
Why did you choose to make it openly available on GitHub?
Moran: GitHub is a free web-based software development platform that provides users with version control and task management features. It’s typically used for managing the development of computer code in so-called repositories.
We thought that an open source repository would be a great way that we could work collaboratively to make the Unicode Cookbook and its associated software tools available online directly to the scientific community.
GitHub also allows us to version the cookbook and to easily keep it up-to-date. It was always our goal to make the Unicode Cookbook open source and GitHub is a great way to do this.
What is the relation between the cookbook and the software packages?
Moran: To implement the work-arounds needed to deal with the pitfalls that we encountered on the Quantitative Language Comparison project, we had to build custom software for working with orthography profiles.
Cysouw and I are specialists in two different programming languages (him R, me Python) and we were a bit stubborn towards adopting each other’s approach. Thus, we figured we would each develop a software package that follows the technological specification for orthography profiles as described in the cookbook. The specification can be implemented by anyone in any programming language, so we thought we could set a nice example of how one might go about implementing the orthography profile specification for text tokenization and transliteration. We also thought we could reach a broader audience if we provided language scientists and programmers with tools in both Python and R.
What are your views on open review?
Moran: Cysouw was signing his name to his reviews before open reviews were fashionable. As a young scholar at the time that really impressed me. I thought it said a lot about his character, but it also brought to light for me some of the problems regarding anonymous reviewing and I questioned why reviewing (in most, but of course not all cases) isn’t more transparent. I welcomed the open reviews of the Unicode Cookbook.
Both reviewers of the book were very thorough and each has made the quality of the book much better given their individual expertises. For example, Sebastian Nordhoff’s review focused mainly on the linguistic aspects of the book. He suggested clarifications regarding the linguistic terminology, so that we could reach a broader audience and he nudged us to write the chapter “Practical Recommendations” on how to input Unicode characters into electronic documents. He is also a keen editor, catching numerous typos and making suggestions for how to better typeset the manuscript.
Our other reviewer was Robert Forkel, a scientific programmer with a strong background in mathematics and programming. In contrast to Nordhoff’s review, Forkel focused mainly on the technological aspects of the Unicode Cookbook. He made invaluable suggestions to the orthography profile technological specification and to the code that we use to process orthography profiles. He also suggested that we make clearer the differences between the technological and linguistic terminology when they overlap — for example, several terms including “encoding”, “character”, and “code” have different definitions in the linguistic and technological literatures.
The two different perspectives from our reviewers helped us achieve our goal of catering to both linguists and programmers. Given Nordhoff’s and Forkel’s valuable contributions, I think it is pertinent that they receive the credit they deserve for taking the time to not only read the book, but to provide us with the many detailed comments that helped us greatly improve it. The open review process allows us to provide attribution in a transparent way (the reviews and the response to the reviewers are versioned in our GitHub repository for all to access).
What are your views on the community proofreading?
Moran: This was my first experience with community proofreading and I think it’s fantastic! We appreciate the fact that so many proofreaders took their time to read the Unicode Cookbook and to point out typos and to make suggestions and edits. If you compare the different versions, you will see that the proofreaders definitely contributed to the overall readability of the book. For example, Alena Witzlack-Makarevich pointed out that we neglect (in nearly a full chapter!) to make any references in the text to the numerous tables that we included. This would have been embarrassing, if published! Hugh Patterson III, an innovation analyst at SIL International, went beyond just proofreading and made many thoughtful comments, some requiring a lot of discussion to resolve. We’re also grateful to Dr. Stephen Pepper, who pointed out with precision many places where we could improve our wording.
We also found that the PaperHive web platform was a nice tool for collaborative reading and community proofreading. We would use it again and have recommended it our colleagues.
Will there be future versions?
Moran: Yes! We will maintain updates and add errata to the book in the GitHub repository. We will then release new versions on GitHub and on Zenodo.
For this project, we try to apply principles of Semantic Versioning from software management practices to publishing. For example, we released our initial draft of the cookbook as version 1.0.0 on February 13, 2017. This is the version that we submitted to Language Science Press for consideration for publication. By putting the first draft online, we made the Unicode Cookbook available to all (this version is even cited in three research papers that use orthography profiles!).
We released version 2.0.0, which indicates a “major” revision, after we addressed all of the reviewers’ and proofreaders’ extensive comments and suggestions. We made a “minor” revision later (version 2.1.0), when we finalized the cookbook for publication by making the final requests for changes from the editors. If we want to make a “patch”, e.g. we find spelling mistakes, we can correct them and then increment the version number, i.e. 2.1.1.
The “available for inspection” link to paperhive has a surplus “.” at the end of the href attribute, making it broken.
thanks, fixed