Since we setup the new servers at CeDiS, we track our usage stats. In this blogpost, I will give some technical details, discuss some conceptual issues and finish with some mathematical remarks.
Technical details
We run Apache as a web server. The logs are analyzed and aggregated with awstats. Awstats also takes care of separating “real users/readers” from “machine readers” (bots). Including the bots would artificially inflate our reader numbers, so it is good to exclude them.
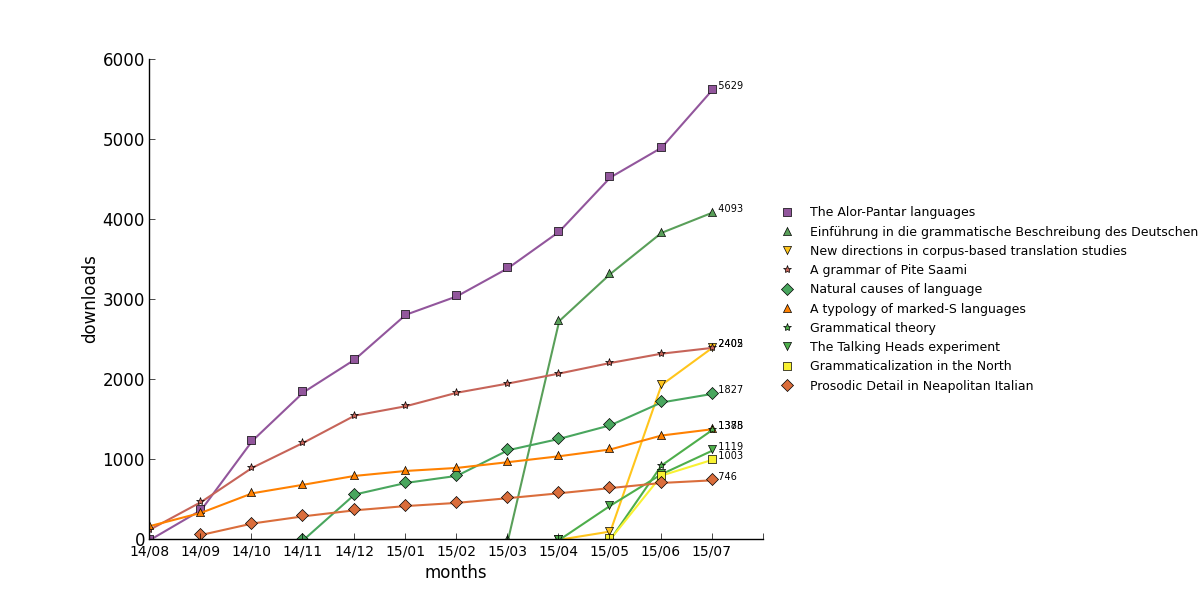
Cumulative downloads for all published books until 07/2105
In the past, we tracked access with a spreadsheet, but we now use an automated routine which parses the awstats output, aggregates access data per book and produces graphics for each book and then again for all books combined (using python, beautiful soup and matplotlib).
Instead of parsing awstats output, we could also access the raw Apache logfiles, but in that case, we would have to take care of the separation between bots and real readers, which is less straightforward than parsing HTML. Furthermore, we avoid legal problems with the protection of privacy by relying on aggregate numbers from the start.
Conceptual problems when counting edited volumes
We offer our monographs as a whole, but for edited volumes, one has the option of downloading individual chapters next to the whole book. Offering the whole book is a service to the readers who are interested in a global view of the topic, whereas chapters are useful for readers who have a very specific interest (e.g. going back to the source when the paper is cited elsewhere). The widespread practice of only offering chapters for edited volumes is very annoying for readers, as they have to reassemble the book locally, which is cumbersome.
However, there are some conceptual problems emanating from this when it comes to usage stats: Suppose we have two edited volumes of 5 chapters each. User 1 downloads the whole book A. User 2 downloads 3 chapters from Book B and ignores the remaining 2. While it is clear that the count for A will be 1, arguments can be made that the count for B should be 0, 0.6, 1, or 3.
The argument for 0 is that only whole books count. This is the approach when doing the stats manually. This is obviously unfair and leads to an undercount for edited volumes as compared to monographs.
The argument for 0.6 is that the user effectively accessed only 60% of the content. But then, one does not know whether user A actually read all chapters either. Furthermore, chapters might be of different lengths, so a lot of interpretation would be necessary to arrive at those numbers.
The argument for 1 would be that a book has either been accessed or not. If it has been accessed, the count goes up by one, regardless of how many parts were accessed. The problem here is that one has to keep track of users. If the three chapters of Book B were downloaded on Monday, Thursday and Saturday, how do I know that it was the same user? What if the user used different devices? What if two users share a network, as often happens in universities? Discounting hits based on heuristics of user identification might lead to an undercount here. (And these heuristics might raise privacy concerns and might even be illegal under German jurisdiction.)
The argument for 3 is that it is rather easy to count. Every hit counts. However, if user A prefers to have a 20 chapter volume in separate chapters, the count is multiplied by 20 as compared to a monograph of the same length! This obviously leads to skewed results.
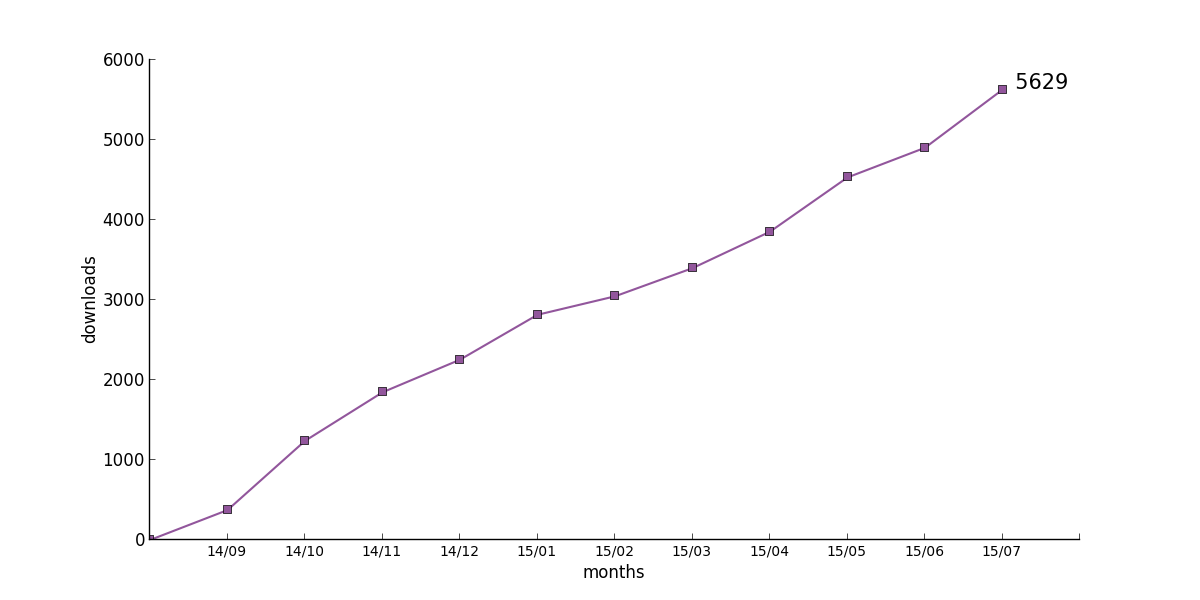
For the time being, we look more at the evolution of numbers for individual books rather than a comparison between books. Therefore, we take the last mentioned approach. This being said, it is clear that a comparison between different books has to take into account whether we are dealing with edited volumes or with monographs. Our current front-runner, The Alor-Pantar languages is an edited volume, which most probably profits from this approach against the runner-up Einführung in die grammatische Beschreibung des Deutschen, which is a monograph.
Conceptual problems with an open approach to publishing.
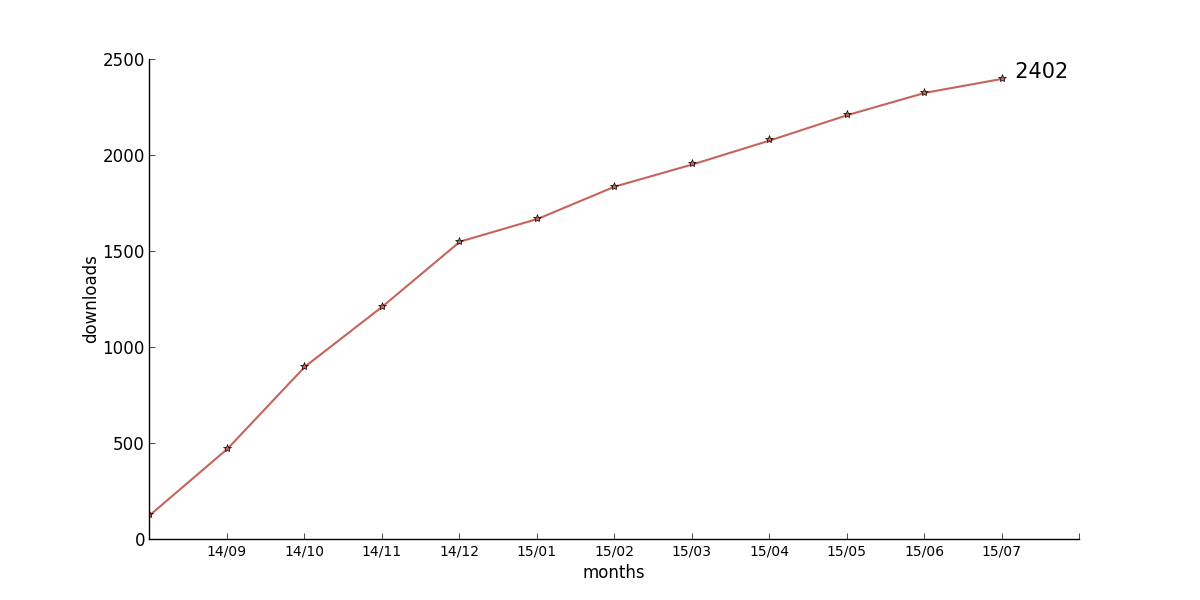
Language Science Press stands for an open access to publishing. This means Open Access on the one hand, but also Open Review and community proofreading. The Open Review versions are being made available to the public via the same platform as the final versions. Furthermore, we are experimenting with community proofreading via hypothes.is for Linguistic variation, identity construction and cognition as well. In all those cases, a pdf (proofreading version, Open Review version, final version) is stored on our servers and being accessed from outside, leading to an increased hit count. The question arises: is this fair? Suppose someone downloads the Open Review version of Grammatical Theory and then, a couple of months later, downloads the final version in order to cite according to good scientific practice. One could argue that the first hit should be discounted. On the other hand, if the user does not intend to cite the book, but has read it with pleasure nevertheless without caring for the amendments of the final version, it is equally unfair to not count this download.
For the time being, we decided to count all hits for a book. This means that books in Open Review will have a comparative overcount. This has to be taken into account when interpreting the statistics.
Mathematical observations
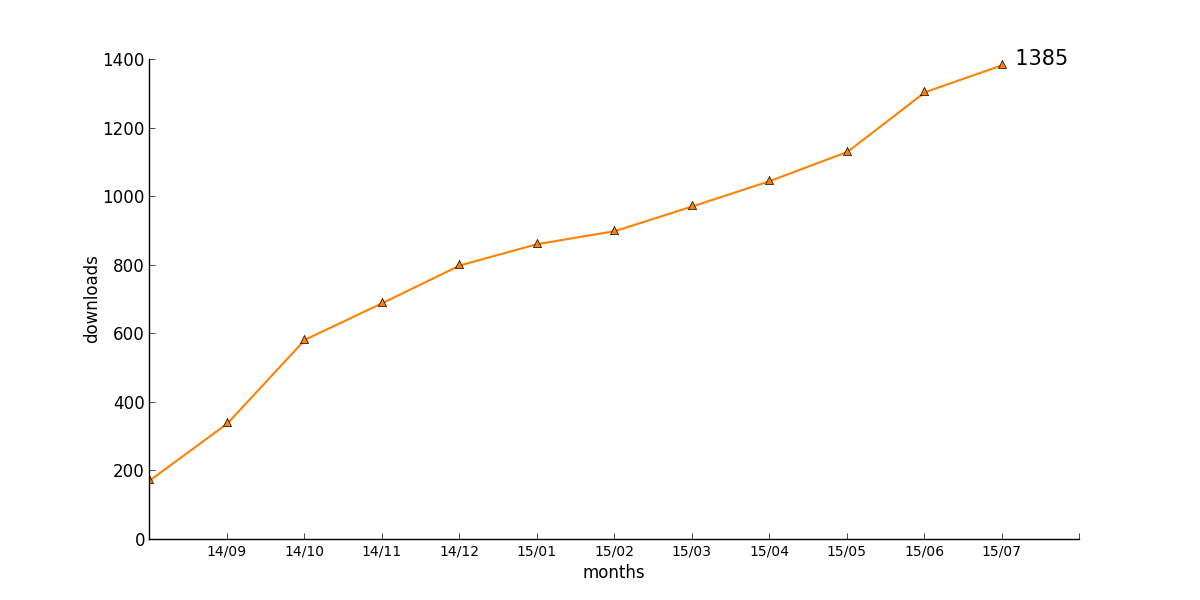
It is intuitively clear that a book will arouse most interest immediately after its publication. As time progresses, less and less people remain who have an interest and do not have a copy. A prototypical time line would be downloads of 1000, 500, 250, 100 in the first months, until the downloads stabilize at a baseline. This leads to a curve with an asymptote, which can be found for many of our books.
Cumulative downloads for all published books until 07/2105
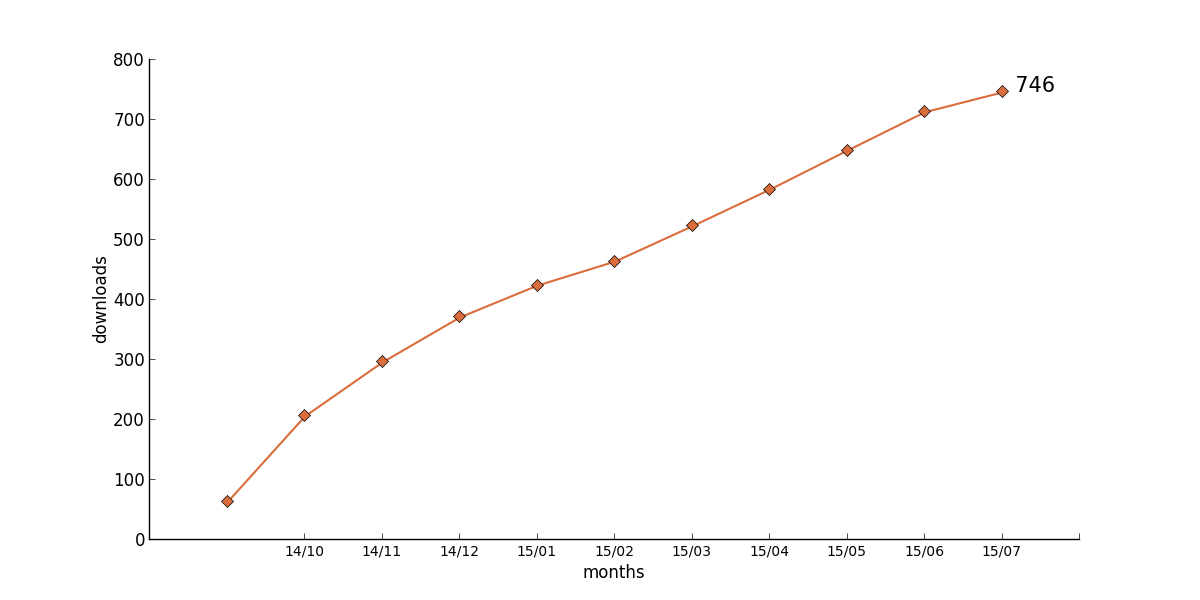
This prototypical behaviour can be found for the following books
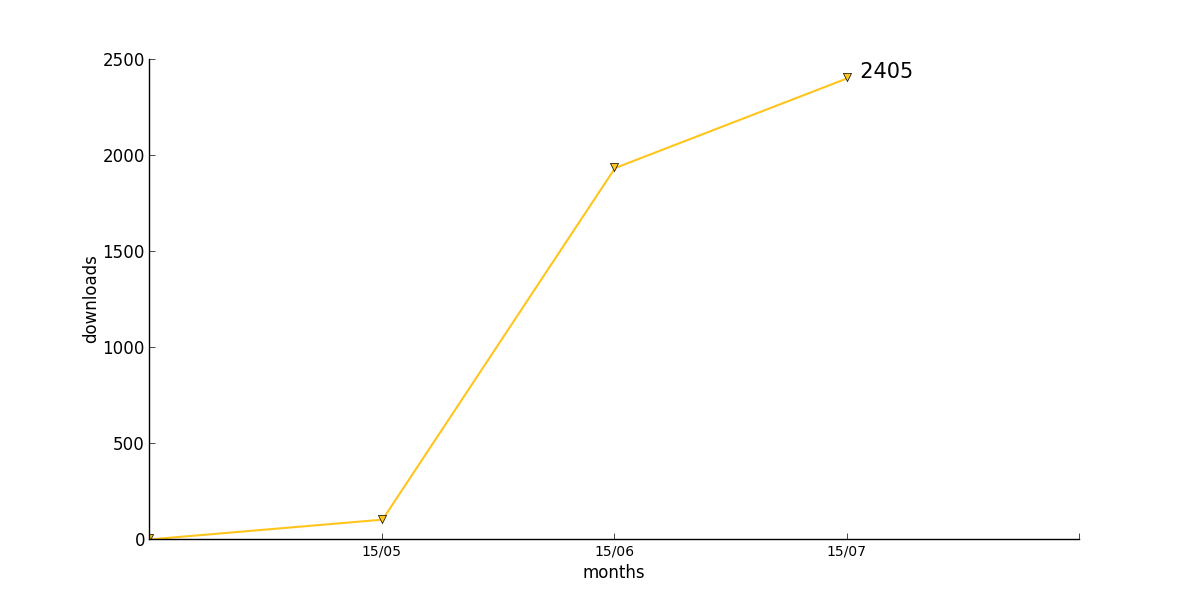
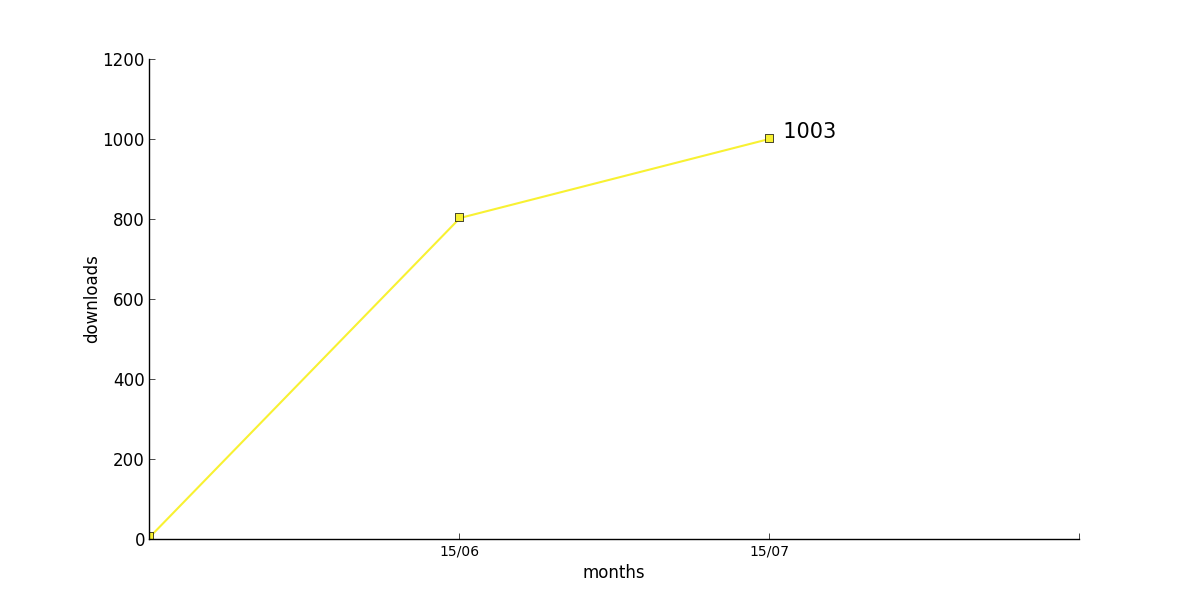
Three books do not show a reduction in download numbers, but seem to involve in a more or less linear way
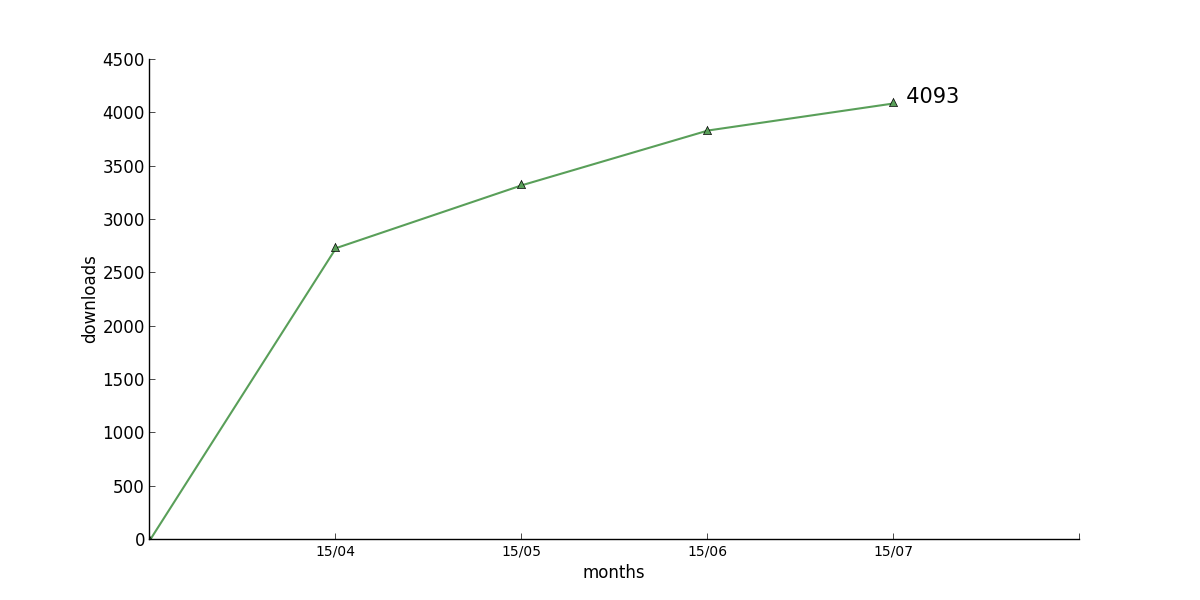
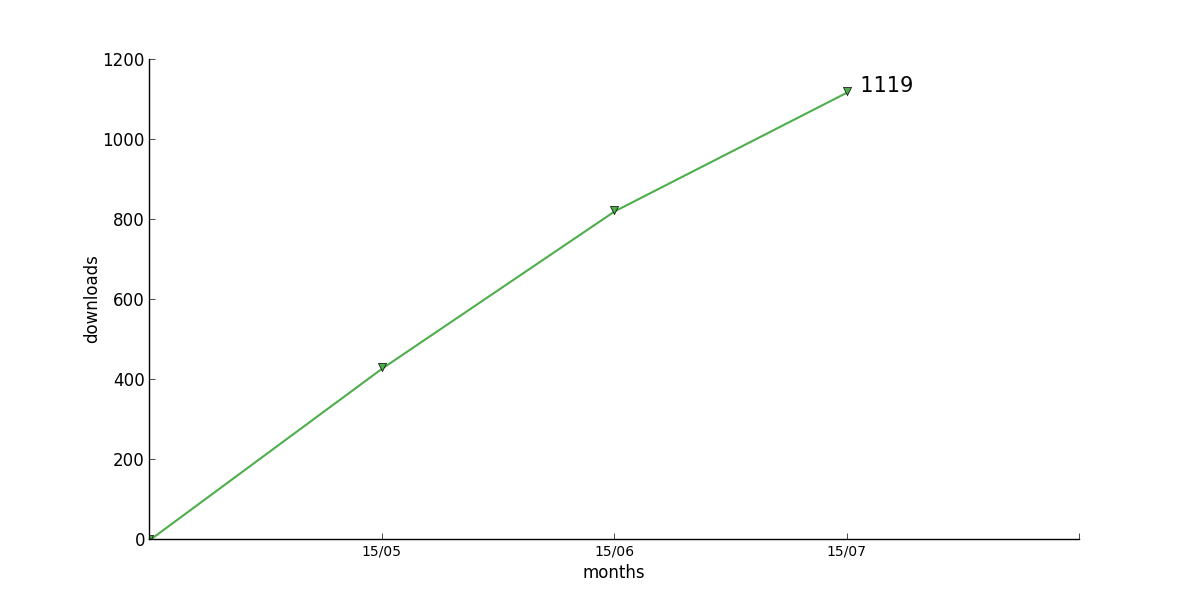
One book finally has a rather bumpy pattern

My guess would be that in the long run, all books should follow an asymptotic pattern, which can be described by a mathematical function. The raw data are available below for people with the necessary mathematical skills.
16 : [None, 63, 206, 296, 371, 424, 464, 523, 584, 649, 713, 746]
17 : [130, 475, 903, 1216, 1554, 1672, 1841, 1956, 2081, 2213, 2329, 2402]
18 : [174, 340, 584, 691, 801, 863, 901, 973, 1047, 1132, 1306, 1385]
22 : [0, 374, 1239, 1846, 2254, 2815, 3046, 3398, 3854, 4532, 4903, 5629]
25 : [None, None, None, None, None, None, None, None, None, 4, 931, 1378]
46 : [None, None, None, None, None, None, None, 0, 2736, 3326, 3839, 4093]
48 : [None, None, None, 0, 568, 713, 802, 1122, 1264, 1434, 1719, 1827]
49 : [None, None, None, None, None, None, None, None, 0, 429, 822, 1119]
73 : [None, None, None, None, None, None, None, None, None, 8, 805, 1003]
76 : [None, None, None, None, None, None, None, None, 3, 106, 1937, 2405]
Thanks a lot for this interesting post and the new download stats! Great to hear that the log analysis is done automatically now.
Two suggestions:
1. “But then, one does not know whether user A actually read all chapters either.” — Well, you never know. I do not assume that the 4093 downloads of EGBD mean that I actually have that many readers. So that’s actually an argument against counting downloads as a meaningful measurement at all.
2. “Furthermore, chapters might be of different lengths, so a lot of interpretation would be necessary to arrive at those numbers.” — If you consider each paper in an edited volume as a single work, length does not really matter. Good editors should also make sure that papers in a volume rarely vary excessively in length (say, 5 pages vs. 50 pages). That said, it might be interesting to see detailed download stats for single papers, especially for the authors of the popular papers in edited volumes.
No, THREE suggestions (“frankincense, myrrh, …”):
3. “For the time being, we look more at the evolution of numbers for individual books rather than a comparison between books.” — Then why do you publish a graph comparing all (types of) books at all? If there are effectively two conceptually different counting strategies for monographs and edited volumes, why not make two plots? Of course, I’m NOT saying this because I want to see my book in the lead again, but because I have serious statistical concerns. I promise. Honestly!
And two comments:
i. Related to suggestion 2: For monographs with many chapters that can be read separately (like Stefan Müller’s “Grammatical Theory” or my “Einführung in die grammatische Beschreibung des Deutschen”), a chapter-wise download and an appropriate counting strategy might also make sense. What colleagues often tell me is that they’re going to use just the chapters on, for example, morphology, syntax, or graphemics for their courses. I’d be highly interested in seeing detailed stats for chapters. This would be helpful for work on future editions as well.
ii. “The widespread practice of only offering chapters for edited volumes is very annoying for readers, as they have to reassemble the book locally, which is cumbersome.” — Couldn’t agree more. Everybody should praise LangSci Press for doing it right!
Cheers!
Roland
@ 2 : we all know that the metrics people are out there to get us. Remember the Impact Factor? Once the metric is established, people will adapt their behaviour. As a result, there might be a competitive advantage in having 20 short chapters instead of 5 long chapters with subchapters, simply to inflate download figures. Yes, this makes little sense from a reader’s point of view; and No, this does not mean that it will not happen. See https://en.wikipedia.org/wiki/Least_publishable_unit
@ 3: the program is agnostic to whether a book has subparts. We would have to store that information elsewhere. We might do this in the future once the graphics get to crammed.
@ i: chapter handling is currently rather cumbersome in OMP (the platform we use). Once this get easier (it is being worked on), we can certainly talk about this.