We started our annual retrospectives in 2015 (2016, 2017, 2018). This is the fifth installment, for 2019.
Books and series
In 2019, we published 30 books:
78 works were proposed to Language Science Press in 2019, for a total of 503. In 2017, 101 works had been proposed.
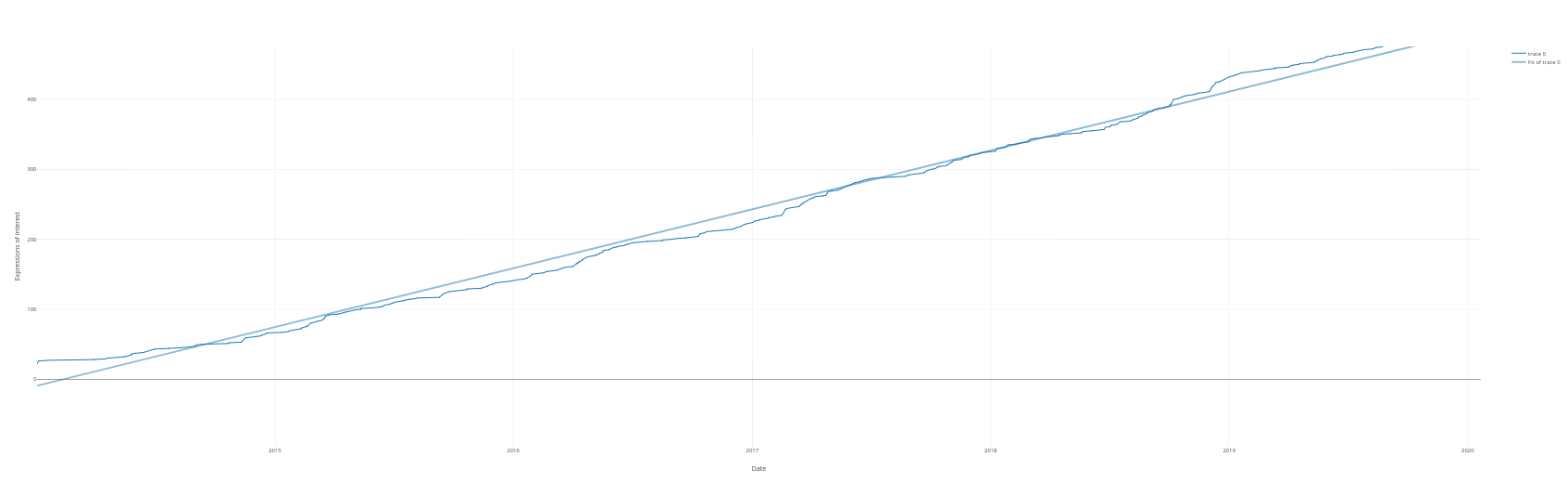
Running expressions of interest 2019
The following figure gives a breakdown of the distribution of these works and their states of completion.
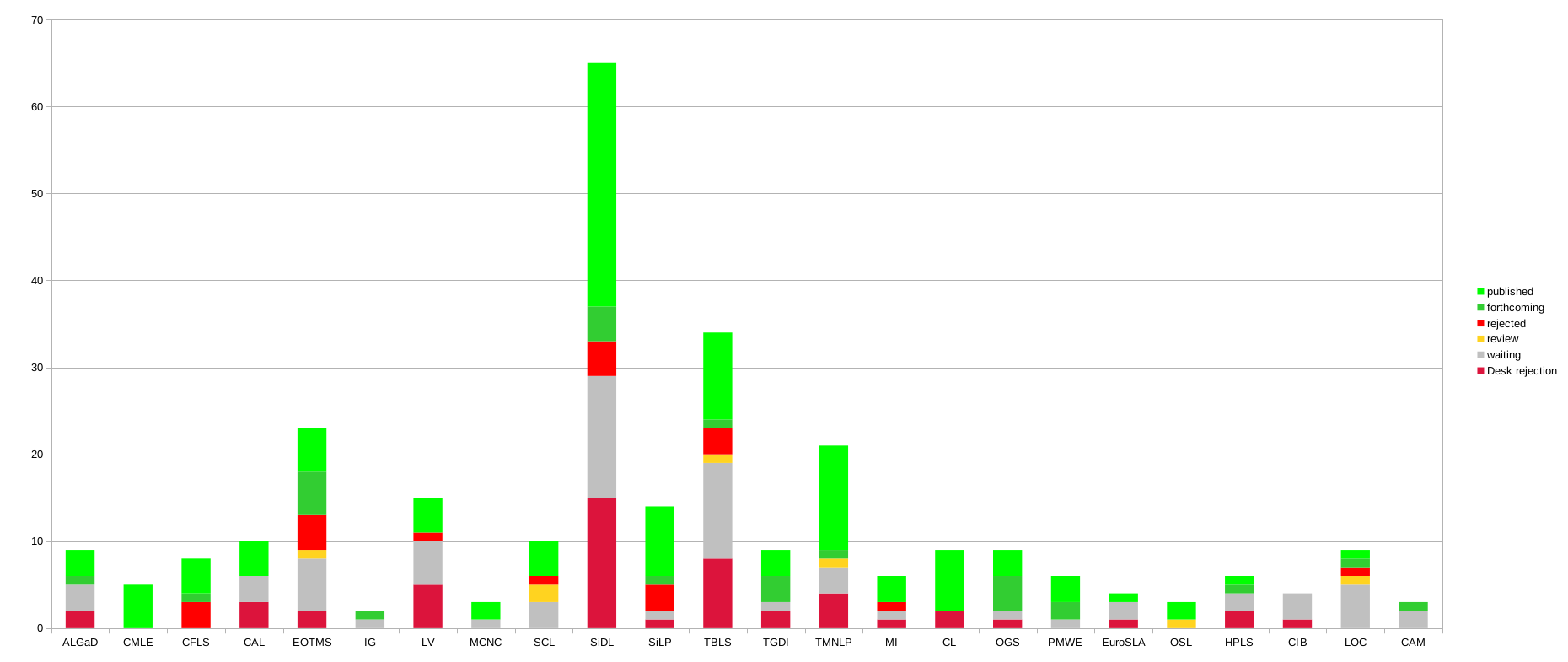 The most active series are Studies in Diversity Linguistics (65), Textbooks in Language Sciences (34), EOTMS (21), and Translation and Multilingual Natural Language Processing (27) [we dropped a couple of promised volumes in the “waiting” category, hence the total numbers are lower than last year.].
The most active series are Studies in Diversity Linguistics (65), Textbooks in Language Sciences (34), EOTMS (21), and Translation and Multilingual Natural Language Processing (27) [we dropped a couple of promised volumes in the “waiting” category, hence the total numbers are lower than last year.].
Series
There are currently 24 series (+2). Last year, we accepted two more series: Current Issues in Bilingualism and Contact and Multilingualism.
The median time from submission to decision is now 98 days (+2). The median time from submission to publication was 271 days (+19).
The acceptance rate (counting desk rejections) is 52.24% (-2.49) over all series. Only considering submissions where the proposal had been previously approved, the acceptance rate is 86.96% (-0.34).
Downloads
In 2019, LangSci pdfs were downloaded 362,983 times (+222,550 compared to 140,433 in 2018), for a grand total of 680,057.
This excludes downloads by search engine robots.
The most popular work is Einführung in die grammatische Beschreibung des Deutschen (all three editions) with 42,013 downloads, followed by The future of dialects, downloaded 35,666 times, and Acquisição de língua materna e não materna (32,802).
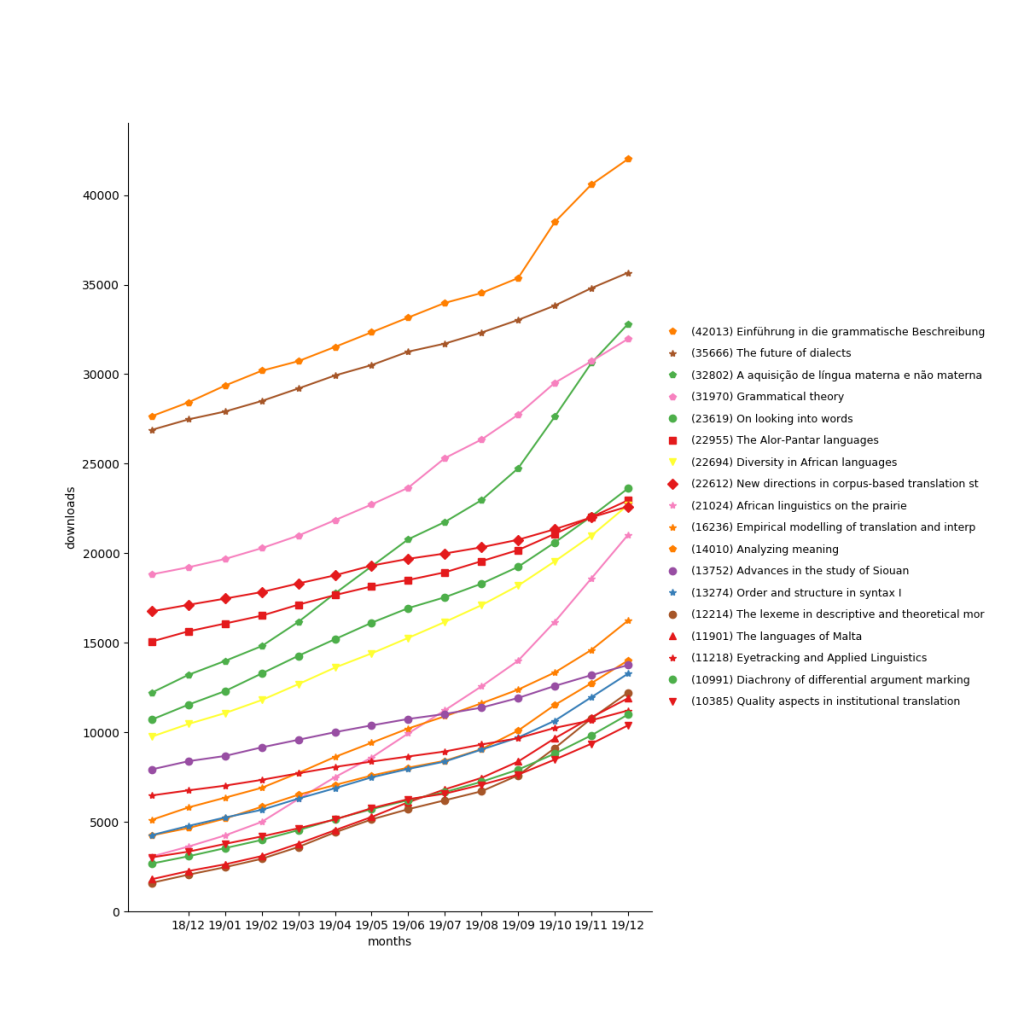
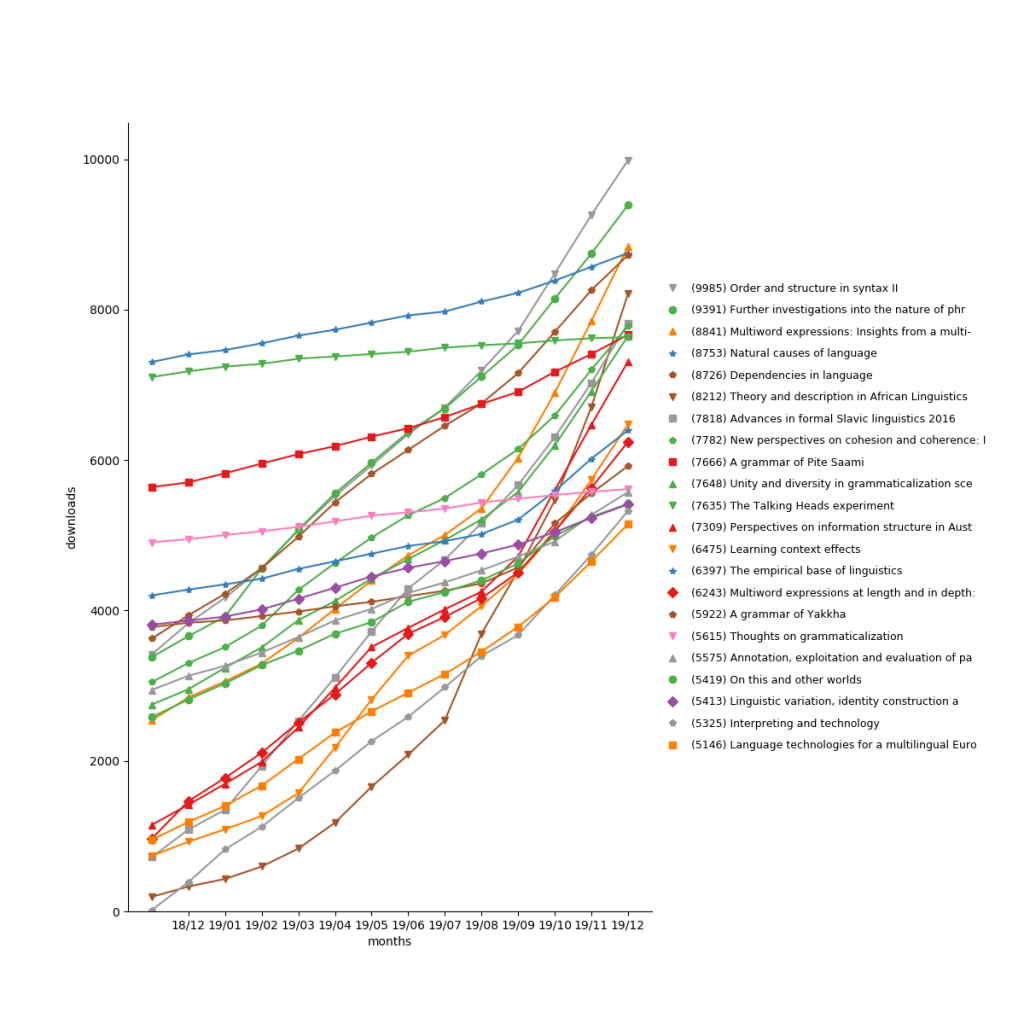
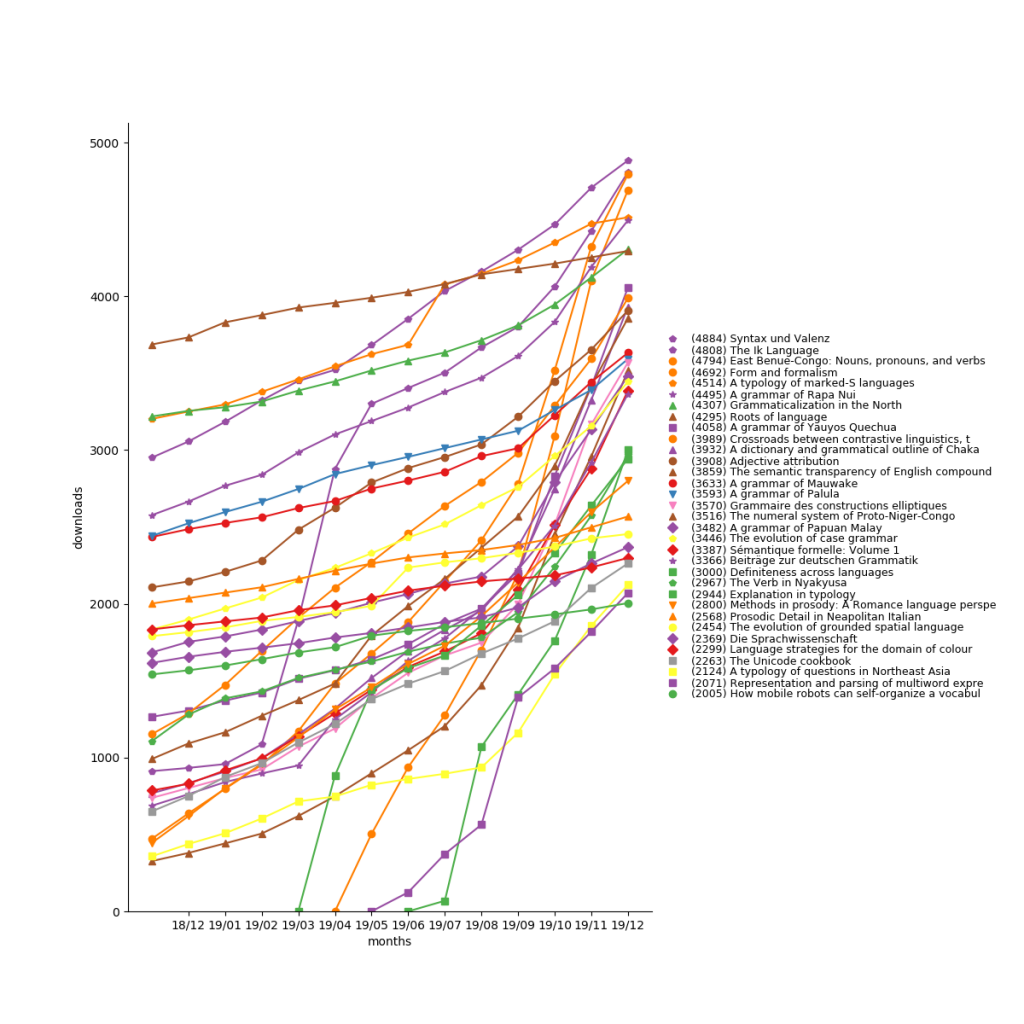
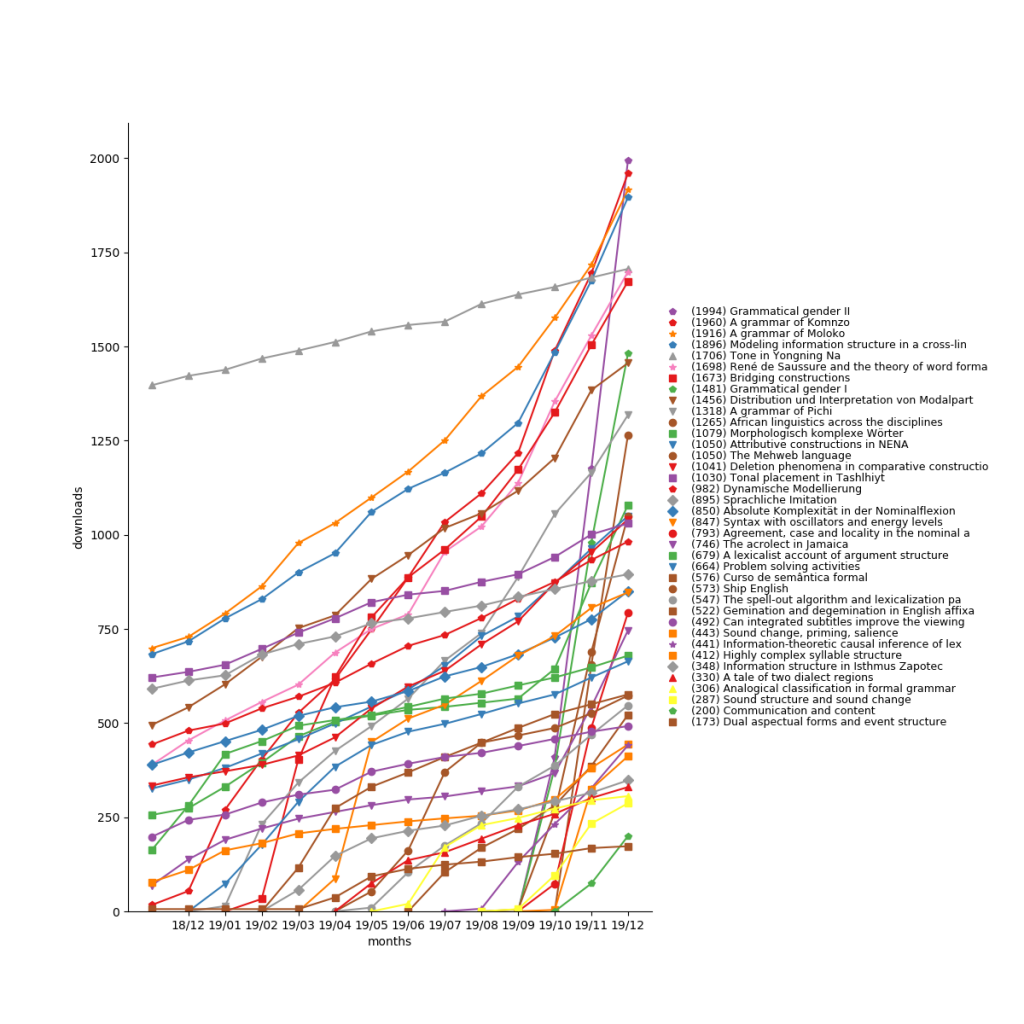
The US has now overtaken Germany as the country with most readers.
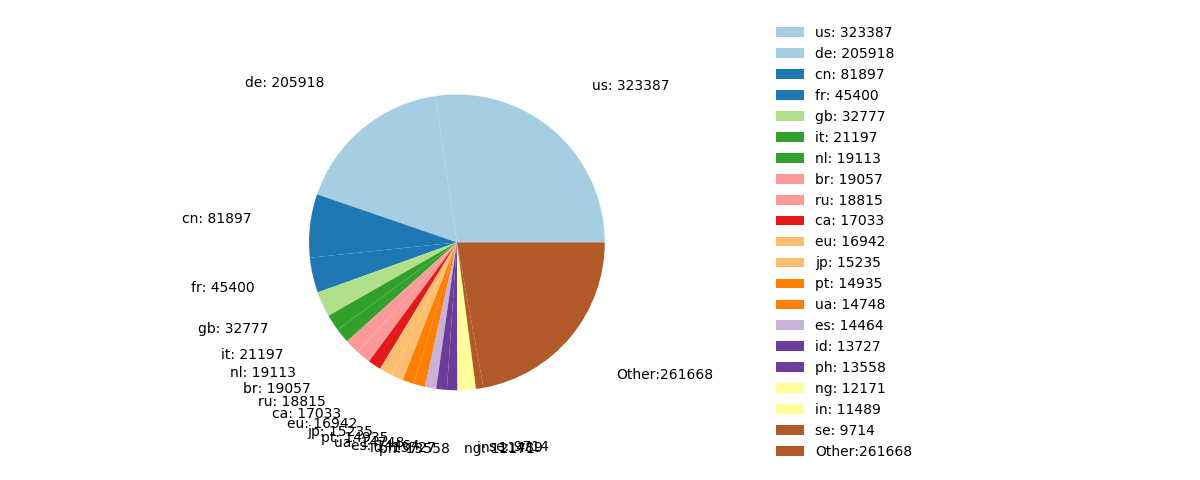
Provenance of readers
Community involvement
Language Science Press is a community enterprise. We rely on the community for authoring and reviewing, but also for typesetting and proofreading. Across all published books, 204 linguists from all over the world have participated in proofreading. The most prolific proofreader is Jeroen van de Weijer, who has proofread chapters of 46 books.
There are currently exactly 400 proofreaders registered with Language Science Press.
Geographical distribution
For our 24 series, we are happy to be able to rely on 342 members in editorial boards from 46 different countries on 6 continents.
Paperhive
We have run 26 of our 2019 books through PaperHive for proofreading, and our full back catalog is available on PaperHive as well. The most comments (2834) are found for Theory and description in African Linguistics. The mean number of comments is 837, the median is 648.
CO₂
For the first time, we try to quantify our CO₂ footprint. LangSci folks have travelled 0km by plane, 9348km by train and 80 km by taxi in 2019, crossing Germany, Austria, Switzerland, Italy, and France. By using the calculators available for the respective national railway companies, we arrive at a total travel-related CO₂ footprint of 35,724g. Compare this to a return trip from Berlin to London by plane, which is 830,000g.
We are currently unable to quantify our electricity and heating CO₂ footprint, but will hopefully be able to do so from 2020 onwards.
Finances
We had a revenue of 132,707.91€ in 2019 and expenditures of 120,001.75€. The main cost items are personnel 75,435.53€, service providers (including rent) 26,778.79€, book copies 5,667.29€, travel 5,461.63€, and gear 3,221.42€. A total of four different employees of four different nationalities have received a salary from Language Science Press (none of them full time, and only one of them 12 months).
Dividing our revenue of 120k by the 30 books we published, we arrive at a very round figure of 4000€ to produce one book (See here for an overview of costs elsewhere, ranging from 8k to 18k€).
The lion’s share of our revenue comes from institutional memberships via Knowledge Unlatched (114,971.50 €). 6961,10 € come from print margin, the rest is diverse.