abgabe:
the term paper is fini. view here.
fangt an zu lernen!
the term paper is fini. view here.
ich werde in dieser arbeit den versuch unternehmen, ein im rahmen empirischer studien durchgeführtes psycholinguistisches experiment ausführlich zu dokumentieren. die studie, welche noch nicht beendet ist, wurde in einem forschungsseminar der bua1 in kooperation von teilnehmern von fu, tu, hu unter der aufsicht der charite durchgeführt. es handelt sich i diesem teil um die partielle replikation des von paula rubio-fernandez (#ref R/F2) unternommenen versuchs, das metaphernverständnis von schizophrenen personen zu untersuchen. dazu wurde in der kontrollgruppe ein self paced reading experiment veranstaltet und ausgewertet.
das experiment hat in einer laufzeit von zwei wochen daten von 46 versuchspersonen erhoben, die hauptsächlich in der statistiksprache R ausgewertet wurden. basis der daten ist die messung von lesezeiten in einem set von 24 items3, die in vierfacher ausprägung literale und figurative elemente in kurzen zusammenhängen verbanden.
Mit Carston (2010#ref carston4) sind wir davon ausgegangen, dasz im experiment zu untersuchende single (SM = Metapher eingebettet in literalen Kontext) und extended metaphors (EM = erweiterte Metapher, eingebettet in weitgehend figurativen Kontext) unterschiedlich verarbeitet werden, wobei durch die notwendige Aktivierung und Reaktivierung der literalen Bedeutung (ad hoc concept) an SM ein höherer Aufwand nötig sei#ref, der im Gegensatz zu EM in einer längeren Lesezeit resultiert. Diese Annahme führt zu folgenden Fragestellungen, die in Anlehnung an ein Experiment (Verifikation/Replikation) von Paula Rubio-Fernandez et al. (2016#ref) hier aufgenommen wurden:
Die zu überprüfenden Hypothesen lauten wie folgt:
Zur Überprüfung der Hypothesen wurde das self paced reading Experiment durchgeführt, das die Lesezeit in den unterschiedlichen Kategorien erfasste.
ich werde im folgenden den aufbau und ablauf des experiments erklären und im nächsten kapitel dessen hypothesengeleitete auswertung erläutern.
die versuchspersonen bekamen während des tests, der online über einen link abrufbar war, ein set aus jeweils 8 items (kontexte) die wiederum die varianten der variable ?einbettung der metapher? in ausprägungen von
enthielten sowie einen bestand aus 16 filler items, die sich ebenfalls in den kontextvarianten unterschieden. die proband/ lasen einen text, von dem jeweils nur eine zeile nicht maskiert war, die jeweils folgende zeile wurde durch das drücken der leertaste sichtbar. so konnte die verweildauer auf einer sichtbaren zeile gemessen werden. als grundlage für die messung wurde ein von (JESPR#ref5) frei verfügbares javascript benutzt, das an unsere bedürfnisse angepasst worden war; u.a. war ursprünglich keine dauerhafte speicherung der daten in einer datei vorgesehen, diese funktion wurde von mir mit einigem aufwand realisiert, so dasz die lesezeiten danach in einer tabelle verfügbar waren. die einbettung des experiments in einen auf der platform soscisurvey.de als akademische studie angemeldeten fragebogen erforderte ebenfalls einigen aufwand, da die randomisierung der itemabfrage in anderer weise als vom script vorgesehen geschehen muszte. die daten selbst enthielten werte für:
die items, die in anlehnung an R/F nach obigem muster von uns entworfen wurden, entsprachen im aufbau dem set, das R/F in ihrem test verwendet hatte; vier ihrer im anhang (#ref) zur verfügung gestellten items hatten wir ins deutsche übersetzt und eines davon als item in vier varianten, die restlichen als filler übernommen. die auswahl der verwendeten items wurde gemeinschaftlich nach kriterien wie konsistenz innerhalb der items, stil und kohärenz bestimmt. ebenfalls nach den constraints von R/F gerichtete vorgaben wie wort- und satzlänge, itemlänge und position des targets hatten beim entwurf eine wichtige rolle gespielt, waren jedoch nicht immer optimal umgesetzt worden; dazu einige bemerkungen im auswertungsteil.
ein item sollte eine metapher in je figurativer und literaler bedeutung, eingebettet in einen je figurativen oder literalen kontext, d.h. also in insgesamt vier unterschiedlichen konfigurationen, präsentieren. die metapher (unser target) sollte sich im dritten viertel des kontextes befinden, um davor und danach auftretende latenzen der lesezeit auswerten zu können. dafür wurden im script des tests die positionen der einzeln zu lesenden phrasen des items mit 0 für das target und je negativen und positiven werten für den abstand zum target festgelegt.6
das set eines einzelnen durch abruf des fragebogens aufgerufenen tests bestand für jede/ studienteilnehmer/ aus einer randomisierten auswahl einer von vier mal acht itemvarianten (aus der menge von 8 items), womit jeweils zweifach meszdaten der vier varianten pro tn erhoben werden konnten, aber niemals ein tn ein item in mehreren varianten las. die 16 filleritems traten innerhalb des sets aus also 24 items an einer zufälligen positionen auf, wurden aber bei allen tn aus demselben pool bedient und wiesen ausgeglichene variation hinsichtlich der figurativ-literalen konfiguration auf.
o.a. daten wurden in R(#ref7) 1. deskriptiv und 2. mittels des paketes lme48 zur erhebung kovariater abhängigkeiten (linear mixed model) analog der vorgaben RF#ref ausgewertet. das script dazu kann hier evaluation, sowie eine erste vom user in einzelnen parametern veränderbare auswertung hier nachvollzogen werden.
zur auswertung wurde die auf einem server durch ein php-script im flachen comma seperated format gespeicherte tabelle in R importiert. um zu gewährleisten, dasz abweichungen hinsichtlich der zeichenanzahl der zeitgemessenen phrasen keine unerwünschten effekte in der berechnung der latenzen zeitigen, wurde bei jeder weiteren berechnung dafür ein von der zeichenanzahl/phrase anhängiger koeffizient einbezogen, der in der ersten, deskriptiven auswertung einfach aus der zeichenanzahl, bei der zweiten kovariaten auswertung mittels lme4 bestimmt (Fine al. 2013,#ref 9) und als residual, hier: korrigierte lesezeit, einbezogen wurde.
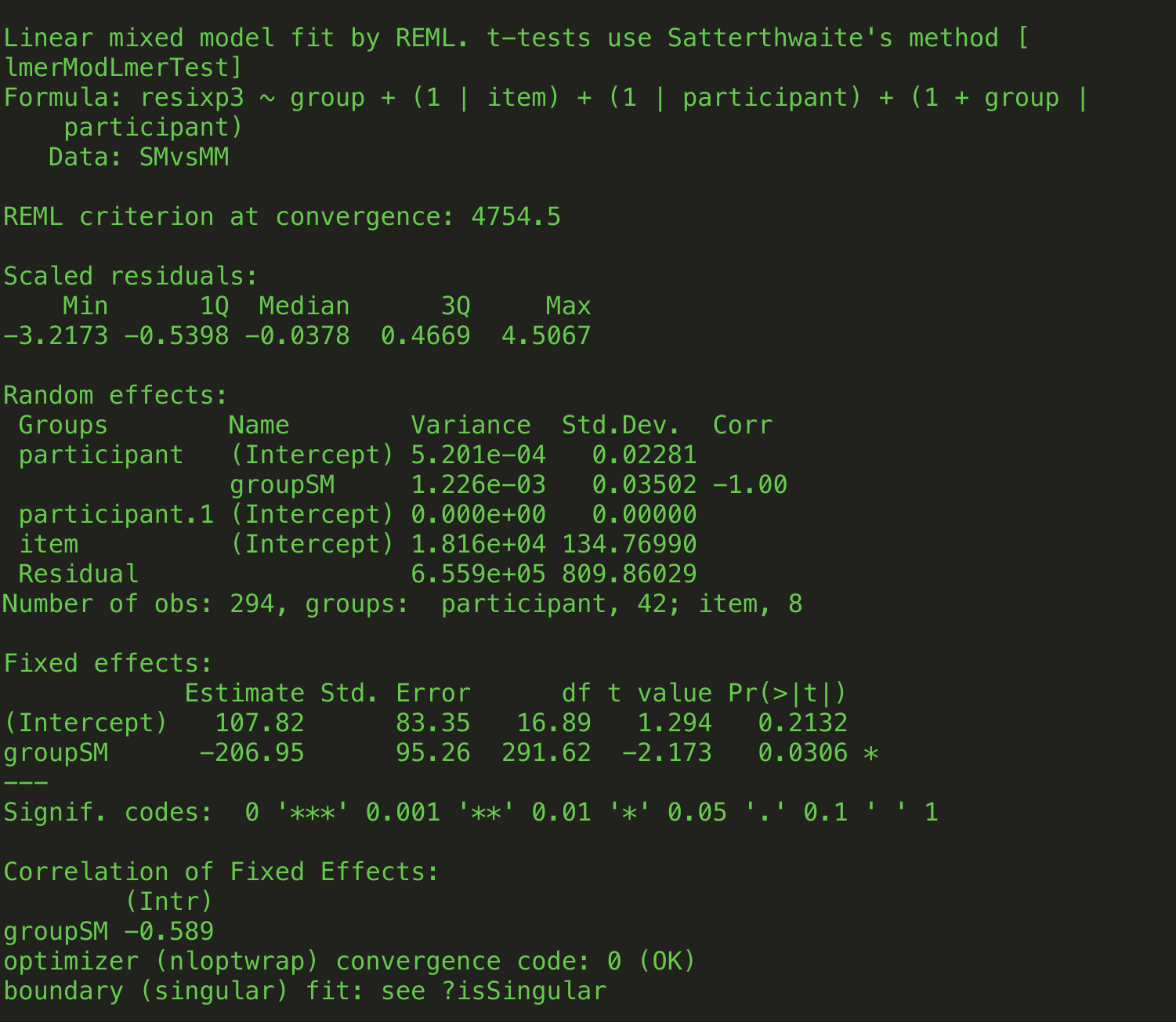
deskriptiv konnten am target keine signifikanten unterschiede in der durchschnittlichen lesezeit festgestellt werden. r/f jedoch hatte ihre daten mit dem r-paket lme4 unter multivariaten gesichtspunkten analysiert. so konnte auch ich (in dieser phase ging die experiment arbeitsgruppe getrennte wege) nach feststellung des effekts der phrasenlänge und berücksichtigung desselben als korrigierte lesezeit, hier: die abhängige variable in der lmer formel, signifikante unterschiede der lesezeiten von ISM und LC feststellen. allerdings nur an dieser stelle, womit einzelne hypothesen nicht bestätigt werden konnten. bei der multivarianzanalyse wurden hier ein main effect der kategorie (lc,sm,em,ism) (group) unter random effects von tn (participant) und kategorie auf tn (group by participant) betrachtet.
ich möchte in dieser arbeit den versuch unternehmen, die deutschsprachige gegenwartslyrik einer kritischen auf multilinguale/neologismische aspekte fokussierten betrachtung zu unterziehen. die arbeit wird weniger close reading als eher statistische verfahren integrieren, um zu einsichten über folgende fragestellungen zu gelangen:
es soll ein korpus erstellt werden, das ein lexikon zumindest der deutschsprachigen gegenwartslyrik enthält. dieses lexikon1 wird distant read ergebnisse liefern können, die aussagen über 1.1 zulassen.2
die arbeit handelt in einem explorativem ansatz, bei dem im vorfeld keinerlei hypothesen aufgestellt werden, da ohne genauere auswertung keinerlei annahmen sinnvoll zu tätigen sind. in einem fazit sollen aussagen darüber getroffen werden, welche rahmung der begriff :postdeutsch: kritisch-literarischen studien bieten kann.
ich werde in der arbeit versuchen, eine erste (einfache) kritische ausgabe des von mir im rahmen des seminars bearbeiteten dramas (Klemm)1 bereitzustellen, die folgendes behandeln wird:
die hausarbeit, auf ein minor paper geschrumpft, kann FYI hier abgerufen werden.
i am applying to your diesjährige meetup with a presentation of an experiment took place within the framework of an inter- and transdisciplinary research project at the intersection of Philosophy, Medicine / Psychiatry, Psychology, and Linguistics, of the Berlin University Alliance (BUA).
since i am not yet able to present with ausgereifte resultate and the research group split up to perform the evaluation i want to focus on the more research practical difficulties we met during our work discussing technical, communication and publishing issues a young group of students may be confronted with.
you will learn about necessities to foresee and details of the experimental design to have in mind :before: it is being made accesible. small details in the design can have great impact on how easy or not you will be able to evaluate the data.
please find an appendix of the experiment in this columns. i would be glad to participating this years meetup to speak about research process in a more common approach. thank you for your attendance, grüsze, st. schwarz, fu berlin.
poster in progress.
da die auswertung u.u. noch nicht abgeschlossen ist, können weitere ergebnisse sobald verfügbar hier eingesehen werden.
zb.:
boxplot der lesezeiten vom targetelement & des preceding & folgenden elements, dh. target -1 / 0 / 1, ohne ausreiszer, 849 observationen, gruppiert nach item und itemvarianten (SM/EM/LC/MM). die lesezeiten wurden hier noch NICHT addiert.
mit dem alternativen script (link) stellt lmertest signifikanzen bei SM vs ISM(MM) fest.
1. model: item ist hier das 4 varianten umfassende item, eines von 8
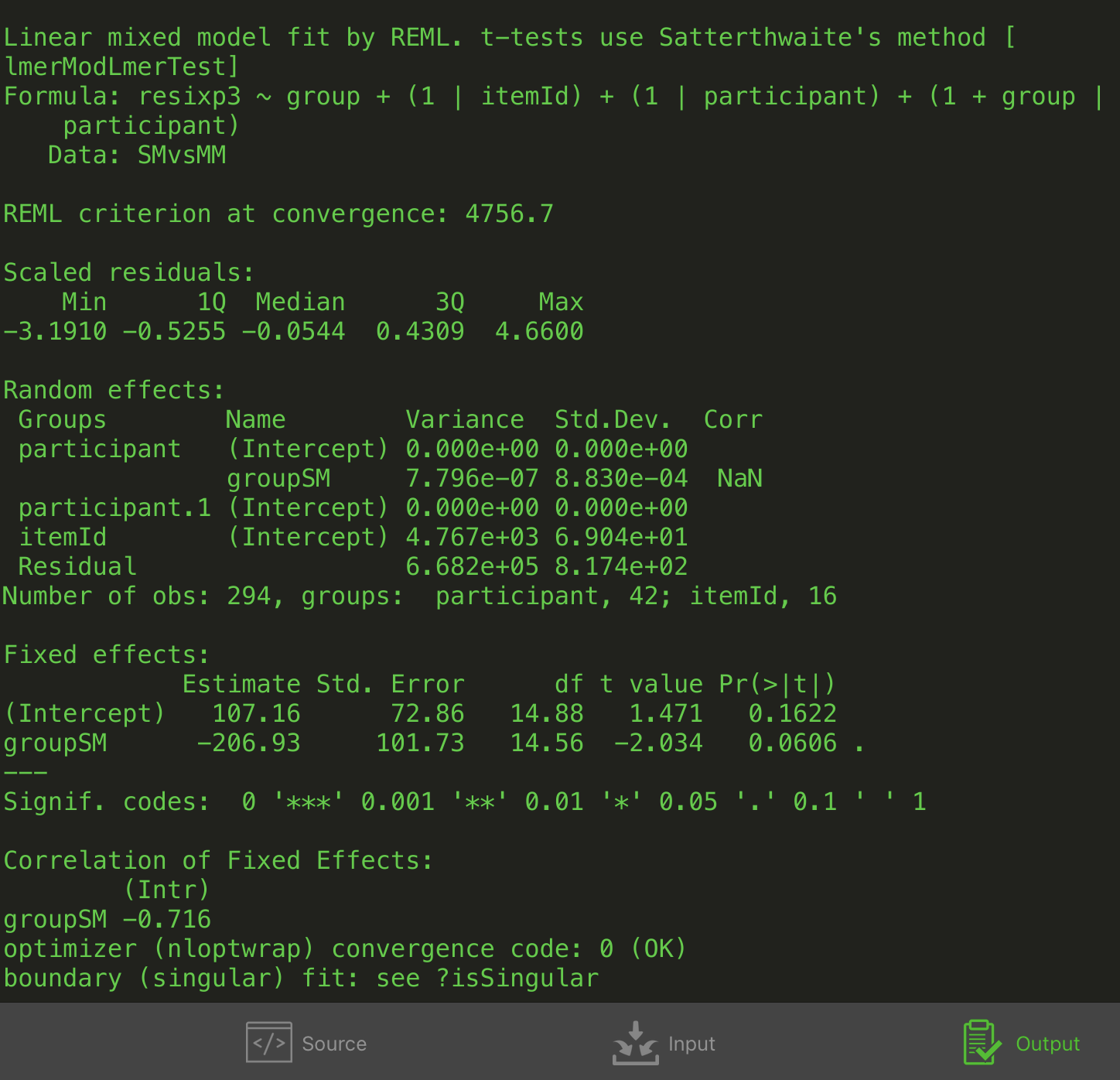
2. model: itemId ist hier das item in seiner variante.
aus rubio-fernandez geht nicht eindeutig hervor, welcher random effekt berechnet wurde, 1. oder 2. in beiden fällen wird mit dem script jedoch ein signifikanter unterschied in der lesezeit festgestellt, anders als mit dem zur auswertung gelangten script 1.
#12375.
die einzelnen samples wurden randomisiert mittels eines fragebogens über soscisurvey den teilnehmern zugeteilt. die daten derer, die den test bis zu ende durchgeführt haben, werden gespeichert.
Sie können die einzelnen abfragen der 8 items hier abrufen, allerdings läuft der test NICHT auf mobilen geräten.
hej lydia…,
da ich nur von dir eine adresse jetzt habe der gruppe gestern, habich dich mal testweise auf dieser seite als admin hinzugefügt oder mache das gleich. eine analoge seite liesze sich dann ohne probleme erstellen, die als pinnwand funktionieren könnte. es müszten nur händisch die emailadressen der fu benutzer eingetragen werden, was ja dann jeder machen kann. ich habe ja nur eine handvoll adressen selbst der kommilitonen, das müszte dann jeder nach belieben aber machen können als admin. also nur ein test, kuck einfach obs klappt… st.
ich versuche an dieser stelle, die arbeit über das phänomen voranzubringen. lassen Sie mich zuerst einiges grundsätzliche anmerken, um miszverständnissen vorzubeugen.
sind in erster linie sprecher, von denen gesagt werden kann, dasz sie die deutsche sprache nicht gut beherrschen. ob es sich dabei um learner handelt, die deutsch zu einem späteren zeitpunkt erworben haben als ihre muttersprache oder um muttersprachler, die die konventionen der deutschen sprache nicht umsetzen können aus den verschiedensten gründen, sei dahingestellt. man wird, wenn man auf das phänomen aufmerksam geworden ist, es in allen möglichen zusammenhängen wahrnehmen und es wird sich nicht immer sagen lassen, woher der kompetenzmangel der jeweiligen sprecher rührt. es handelt sich hierbei um sprecher aller möglichen geschlechter, ich spare mir jedoch redundante referenzen aufwendig zu markieren, da mir eine differenzierung nach verschiedenen genderidentitäten in der hauptsächlich untersuchten altersgruppe durch eine auf MÄNNliche/WEIBliche und nicht neutrale identifizierung abhebende pronominalisierung zumindest meinem verständnis der dt. sprache nach unangebracht erscheint.1
wir werden uns in folge über einige begriffe klarheit verschaffen müssen, um über das phänomen einig zu werden. wir haben es mit einem zuerst von mir subjektiv so wahrgenommenen (phänomen) zu tun, über welches konkret ich bis jetzt keine untersuchungen finden konnte. die angestellte hypothese also ist z.zt. noch sehr gewagt, darüber bin ich mir bewuszt. ich hoffe, zu dieser im folgenden einiges formulieren zu können, das zumindest ihren nachvollzug ermöglicht, so absurd sie weiterhin einigen erscheinen möchte.
an dem satz [ich hatte die eier gezählt] vermissen wir intuitiv eine nicht besetzte position. diese musz entweder durch den kontext, in dem der satz (als antwort zb. auf: [woher wusztest du, dasz ein ei fehlte?]) oder durch die fehlende adverbiale bestimmung [vorher] ausgefüllt werden, damit er sinnvoll verstanden werden kann. dieser (aspekt) weist beim plusquamperfekt auf ein notwendiges potenzial hin, welches umgesetzt wird, wenn die bedingungen (spezifizierungen) erfüllt sind.
und wiszt ihr was das schöne ist an dieser gegen-den-strich? wer durchaus an dem phänomen interessiert ist, kann genau hier den fortgang der arbeit verfolgen. so sorry no video, you have to click yourself durch. fullscreen wäre eine alternative gewesen…
das war n biszchen vorschnell publiziert…, die graphischen (erkenntnisse) sind nur sichtbar mit login ins lms der fu. i elaborate on that…
first insights:




im just playing along…





auch geil: nur was soll der unsinn…


okay…, schon das erste problem: es wäre schön gewesen, die jeweils zustandegekommenen werte 1 (keine zustimmung) bis 4 (super zustimmung) addieren zu können über die datensätze hinweg. damit hätten wir eine sehr fein abgestufte skala (diagramm) bekommen, wie man sieht. da aber (mein fehler, jetzt korrigiert) :keine antwortpflicht: bestand…, cvd auch werte wie -9 für eine nicht beantwortete frage auftauchen (siehe EMPATHISCH) läszt sich das jetzt nicht mehr :so: einfach machen. hat jemand eine idee? man könnte hier für alle -9 eine 2,5 einsetzen, oder? also den median zwischen 1 und 4? dasselbe problem bei ungleichen anzahlen von datenreihen für GS / beidnennung, cvd 7 reihen für GS und 5 für BN ergeben dann unterschiedliche summen. wenn wir allerdings mit dem durchschnitt rechnen (was obiges problem lösen würde, hätte wir keine detaillierte abbildung mehr, was auch schade ist… i elaborate on that…
> mit durchschnittswert, alle -9 entfernt:

data_spund003_2021-01-01_09-45EVALdiagramm.jpg




> ich nehme die antwortpflicht wieder raus. es wird für autisten immer noch schwer sein, alle fragen zu beantworten, es sind ein paar -9 codes aufgetaucht, was eine addition der codes 1-4 und damit abbildung auf der menge der antworten sowieso nicht mehr ermöglicht. es ist besser ein paar unvollständige bögen zu haben als solche, die wegen frust über unmögliche antworten abgebrochen werden… / ich habe für meine grafiken das geomittel gewählt, das die antworten multipliziert und durch die wurzel der anzahl antworten teilt.




ich werde hier ab jetzt dann nur noch den datensatz aktualisieren, er hat den datumsstempel im dateinamen, werdet ihr dann sehen, von wann das jeweils ist…
die variablen sind:
QU02_1 bis _38: bogen mit glottalstop in der ersten abfrage
QU07_1 bis _38: bogen mit beidnennung i.d. ersten abfrage
QU08_1 bis _38: bogen mit glottalstop i.d. zweiten abfrage
QU09_1 bis _38: bogen mit beidnennung i.d. zweiten abfrage
guten morgen gruppe…,
die samples von anabelle sind integriert in den bogen und dieser soweit fertig mit den neuen änderungen. ich fänds nur gut, wenn ihr vielleicht nochmal die meta geschichten ankuckt…, also alle beitexte, die zu lesen sind, einführer usw., weil diese ja auch die umfrageergebnisse beeinflussen, also meine wortwahl für alles, was zu lesen ist. können ja kleine sachen sein, die euch auffallen aber mir eben nicht. soll ich dafür ein ultimatum setzen? machich einfach bzw. kann man ja jederzeit sachen ändern, wenn jemandem, oder auch von euren testpersonen, noch was auffällt.
also hier: https://www.soscisurvey.de/spund003/?q=basernd <<<<< (diesen link verschicken!)
der link zum bogen, der dann beim aufruf zufällig mit dem glottal stop sample oder der beidnennung startet. wir haben dann pro sample über die befragung verteilt auch zwei datenreihen, die nochmal eine genaue aufschlüsselung erlauben, falls uns zum thema „die leute wissen, worauf die befragung abzielt“ nochwas einfällt bzw. wir können die verzerrung im unterschied der ergebnisse beobachten (das ist eine hypothese, oder?) die dann jeweils für den erstabruf oder den zweitabruf im fragebogen herauskommen. natürlich kann man, sollte es keine signifikanten unterschiede geben, beide reihen auch als eine interpretieren und hat dann natürlich die doppelte menge an daten. ich hoffe, ihr habt das alle verstanden, was an dem zufallsprinzip (mir jdfs.) so wichtig war. es macht für das prozedere selbst keinen unterschied.
wichtig: wir müssten uns nur verständigen darauf, den bogen dann nicht mehr testweise aufzurufen, bzw. ihr müsst, wenn doch, dann peinlich genau die zeit dokumentieren, wann ihr darauf zugreift, dann kann man diesen datensatz von der auswertung ausschlieszen. ich sehe keine ip-adressen oderso, sondern nur die zugriffsdauer, start/ende.
okay…, hoffe es kuckt einer demnächst hier rein, (ultimatum?): der link kann dann wie o.a. verschickt werden, je früher desto besser.
ich stelle hier nochmal die abrufbaren daten, wie momentan gültig, als anhang ein.
data_spund003_2020-12-31_11-28.csv.tsv > ihr seht, der letzte datensatz hat die nummer CASE 61.
values_spund003_2020-12-31_11-30.csv > das sind beides variablenschlüssel, um die datenreihen zu verstehen
variables_spund003_2020-12-31_11-29.csv > -||-
data_spund003_2020-12-31_11-30.csv.tsv > das ist dasselbe wie oben, nur mit den antwortcodes in der tabelle stehend, die dadurch sehr in die breite geht… / also zum ankucken ganz gut, aber zur extraction der datenreihen obiges besser geeignet.
u.u. müszt ihr die .tsv endung entfernen, bevor ihrs öffnen könnt? das ist das format, indem ich es hier laden tue von soscisurvey. also .csv sollte als endung geeignet sein, es in excel whatever zu öffnen. (ich sehe, es wird auch so, mit .tsv endung geöffnet…)
guten morgen les etudiantes… / habe schonmal zwei samples improvisiert und den fragebogen aktualisiert. es sind z.zt. mehrere mögliche abfragen drin, je nach link, der weitergegeben wird, der fragebögen besteht aus zwei identischen seiten, die sich nur durch das (ebenfalls bis auf die variable identische sample) unterscheiden.
zufällig > https://www.soscisurvey.de/spund003/?q=basernd
mit glottalstop zuerst: https://www.soscisurvey.de/spund003/?q=basegs
mit suffixen zuerst: https://www.soscisurvey.de/spund003/?q=basesfx
also entweder gezielt an leute die verschiedenen links schicken oder den -basernd- link zur zufallsauswahl. (ich wäre eigentlich dafür, nur ein sample pro bogen bzw. teilnehmer abzufragen, wir kriegen die ergebnisse aus der ersten und zweiten abfrage nicht mehr auseinanderdividiert cvd. die von mir angenommene verzerrung durch die fehlende verschleierung des ziels wird nur durch sehr viele teilnehmer relativiert. wenn jeweils nur ein sample bewertet würde, erübrigt sich das. bei der zufallsauswahl besteht dann natürlich das risiko, dasz die gewichtung glottalstop / suffixe nicht mehr gleich verteilt ist also unterschiedlich viele teilnehmer die jeweiligen bögen beantworten, das ist aber wohl nicht so schlimm, wie die angenommene verzerrung finde ich…
bisheutabend…
> samples:
update 1443: das mit den zwei samples in einem fragebogen hat sich erledigt, ist doch kein problem… / bin am basteln. alles nur eine frage, wie man die daten dann auswertet. wir haben dann pro sample zwei datensätze / teilnehmer, einmal den, der bei den teilnehmern als erstes erschien, und zweitens den, bei denen dasselbe sample als zweites erschienen ist.
ein problem könnte jedoch auch darin bestehen, dasz wir uns ja eventuell für einen sprecher entscheiden unter uns? das könnte man ebenfalls umgehen, indem wir noch mehr varianz in die bögen bringen und zb. auch zwei verschiedene sprecher und samples integrieren, die dann eben auch nur zufällig erscheinen, aber etwas unsere eigenen stil-färbenden elemente nivellieren, oder… / die ergebnisse kann man dann natürlich nur unter den sprechern selbst gegeneinanderlesen, aber bei genug teilnehmern gibt es vielleicht auch dann erkenntnisse…
nochwas: ihr könnt mal probieren, wenn ihr euch mit soscisurvey vertraut machen wollt, das zu importieren in ein eigenes projekt…, also die rubrik fragen selbst bearbeiten… / es ist zwar sinnvoll, wenn das nur einer von uns weiter entwirft, aber so könnt ihr euch das eben auch mal ankucken… > package_questions_2020-12-30.xml müszt ihr runterladen und dann in soscisurvey als rubrik importieren…
und: falls schonmal jemand die auswertung wagen will, zwei datensätze + variablencodes usw., damit ihr damit was anfangen könnt. viel spasz…
es wäre gut, etwas schriftlich :komsepsionelles: von jedem zu haben, das wir dann zusammengieszen können, so dasz am ende ein text zur studie vorhanden ist oder vorlage für die präsentation, d. wir vielleicht als komplettpaket begleitend hier für alle andern des kurses hochladen können? > ich bin nicht für eine powerpoint, wenn das aber jemand anders sieht und ansprechend gestalten kann, auch gut. mir liegen blanke texte mehr…