Linguistic data is often presented in a wide range of glyphs with many modifications on them, such as accents, and from a variety of scripts: á, ô, ẅ, ɖ, ɓ, ð, ʎ. These typographic demands put considerable constraints on font selection. At Language Science Press, we use Libertinus for Latin and Greek base glyphs and modifications.
Our workflow at Language Science Press is built on free and open software (FOSS). Most prominently, we use XeLaTex as a typesetting engine to produce our books. But the fonts we use to typeset our books can be considered FOSS as well. One advantage of using actively maintained FOSS fonts is that improvements to the fonts can be applied in a very short time frame, which enables us to accommodate authors’ needs very quickly.
This blog post is about how particular requirements arising from different books can be accommodated by extending the open Libertinus font.
Coverage as a factor in font selection
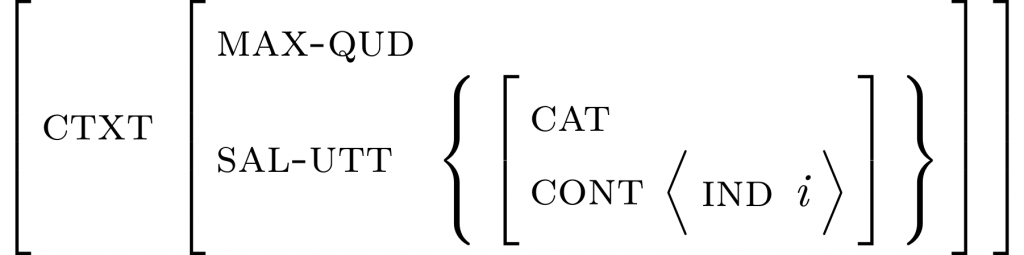
Selecting a font can be a complex issue, especially for a scientific publisher in linguistics. For one, font selection is a matter of layout and aesthetics. But there’s also a more technical side to it, and that concerns coverage: it should not be necessary to switch the font for particular glyphs. By offering to publish in a diverse range of sub-disciplines, the fonts for a linguistic publisher must provide all the glyphs needed by those disciplines. For our Studies in Diversity Linguistic series, we need a high coverage not only in Latin base glyphs, but in accents and diacritics as well. On the other hand, our Empirically Oriented Theoretical Morphology and Syntax series depends on typesetting formulas with all sorts of logico-mathematical symbols, such as relations, operators, variables, delimiters, etc.: ①, Σ,→, ⟦…⟧ Additionally, our quantitatively oriented series profit from mathematical type of numbers and equations (as in “p < 0.005”).
Continue reading