Shelece Easterday and Nadine Grimm won the Greenberg Award and the Pāṇini Award, respectively, both awarded by the Association of Linguistic Typology at its 2019 meeting. Both have chosen to publish theirbooks with Language Science Press. Let’s see what they have to say about their motivations and their experiences.
Hi Shelece and Nadine, and congratulations to your awards from the Association for Linguistic Typology. Could you tell us briefly what your research is about, and why you received the awards?
Shelece: My research is in phonological typology, and I am particularly interested in rare sound patterns and how these come about through processes of language change. My 2017 dissertation, for which I received the 2019 ALT Greenberg Award, examines the properties and emergence of highly complex syllable structure, a phonotactic pattern in which long strings of consonants may occur. My study involved both quantitative and qualitative analysis of the phonetic, phonological, and morphological properties of a diverse sample of 100 languages in order to determine the dynamic processes that might lead to a language developing highly complex syllable structure. I believe that it was the combination of this approach and the interesting topic (a pattern which is famous in the literature but often theoretically marginalized) which made the work attractive to the award committee.
Nadine: I work on the Gyeli language of Cameroon and other Bantu languages. Based on empirical primary data that stems from fieldwork in the language community, I pay special attention to the interface between sound, meaning, and syntactic structure. In addition to grammar writing, I am especially interested in systems of grammatical tone as well as aspects of anthropological linguistics, for instance numeral systems or color terms.I received the Pāṇini Award 2019 for A grammar of Gyeli, an endangered northwestern Bantu language of Cameroon spoken by “Pygmy” hunter-gatherers. The award committee praised the originality of the grammatical analysis, which is solidly based on empirical evidence from a diverse range of natural language data, the fact that the grammar is thoroughly embedded in and explicitly connected to wider scholarship in both Bantu linguistics and typology, as well as the accessible, reader-friendly form-to-function style in the grammar’s organization.I believe that another bonus of the grammar is its foundation in a documentary approach. Nineteen months of fieldwork within a DoBeS (Documentation of Endangered Languages) project provided a rich text corpus covering various genres that informed my description and enabled me to add ethnographic and sociolinguistic information.
Linguistic data is often presented in a wide range of glyphs with many modifications on them, such as accents, and from a variety of scripts: á, ô, ẅ, ɖ, ɓ, ð, ʎ. These typographic demands put considerable constraints on font selection. At Language Science Press, we use Libertinus for Latin and Greek base glyphs and modifications.
Our workflow at Language Science Press is built on free and open software (FOSS). Most prominently, we use XeLaTex as a typesetting engine to produce our books. But the fonts we use to typeset our books can be considered FOSS as well. One advantage of using actively maintained FOSS fonts is that improvements to the fonts can be applied in a very short time frame, which enables us to accommodate authors’ needs very quickly.
This blog post is about how particular requirements arising from different books can be accommodated by extending the open Libertinus font.
Coverage as a factor in font selection
Selecting a font can be a complex issue, especially for a scientific publisher in linguistics. For one, font selection is a matter of layout and aesthetics. But there’s also a more technical side to it, and that concerns coverage: it should not be necessary to switch the font for particular glyphs. By offering to publish in a diverse range of sub-disciplines, the fonts for a linguistic publisher must provide all the glyphs needed by those disciplines. For our Studies in Diversity Linguistic series, we need a high coverage not only in Latin base glyphs, but in accents and diacritics as well. On the other hand, our Empirically Oriented Theoretical Morphology and Syntax series depends on typesetting formulas with all sorts of logico-mathematical symbols, such as relations, operators, variables, delimiters, etc.: ①, Σ,→, ⟦…⟧ Additionally, our quantitatively oriented series profit from mathematical type of numbers and equations (as in “p < 0.005”).
Keyword (or keyterm) extraction is the task of automatically identifying the terms that best describe the contents of a document. It is the most important step in generating the Subject Indexes that you can find in the back of many of our publications.
Up until now we’ve been using Sketch Engine to accomplish this. Sketch Engine is proprietary software that offers many pre-compiled corpora to compare your own texts against. For example, we would upload the raw text of a new book and compare it against the British National Corpus, an extensive collection of various English language texts from the late 20th century. Since linguistic publications usually have a vocabulary that is quite different from everyday language, Sketch Engine did a good job at filtering out the terms that were unique to our book – resulting in a list of keyterms such as language acquisition or vowel harmony.
So why fix something that isn’t broken? Because we are committed to using free and open software wherever possible, and also to making things easier wherever possible. We wanted our own, local, open source keyword extraction software. As an intern with Language Science Press, I was tasked with developing that software. It should work just as well while being easier to use and possibly more tailored to the linguistic domain.
Keyword extraction models
The following paragraphs will demonstrate different approaches to keyword extraction. For illustration purposes we’re going to look at terms extracted from a forthcoming volume of papers from the 49th Annual Conference on African Linguistics. This book represents a wide variety of linguistic disciplines while adhering to the latest LangSci standards, and since I was involved in typesetting I’m somewhat familiar with its contents and possible good key terms.
Sketch Engine
First, let’s take a look at our baseline, Sketch Engine:
Since our books are written using the typesetting system TeX, one important thing to consider is whether to feed the software the raw TeX code, including all the formatting commands and linguistic examples, or a so-called “detexed” version that ideally only contains the actual text.
The current workflow needs a detexed version, so we use the detex software that comes with TeX Live. We upload the resulting text file to the Sketch Engine web interface and compare it against a reference corpus with a few clicks. The resulting list can be exported to a spreadsheet format.
noun class
matrix clause
head noun
dā gbáŋ
amba rc
object agreement
vowel system
focus particle
focus marker
proleptic object
buy book
countable mass
subject position
direct object
atr harmony
external argument
tex localbibliography
sentence final focus
final focus
grammatical role
As you can see on the right, the top 20 results are generally good. Some terms need manual editing (e.g. complete countable mass to countable mass noun, count noun and mass noun – see chapter 14) while others should be removed, namely parts of linguistic examples (dā gbáŋ and buy book) and TeX commands (tex localbibliography) that appear even though we detex’ed the document!
Martin, you started the project of a scholar-owned press in 2013, together with Stefan Müller. How did you get involved in Language Science Press, and what can you tell us about the developments and your experience?
Martin Haspelmath
One day in 2012, I received a message from Stefan Müller (then at FU Berlin), who asked me if I wanted to get involved in a project for bottom-up open-access publication in linguistics. We had not met before, as we belong to somewhat different communities (I’m a typologist, and Stefan mostly works on the formal syntax of German), but after our first meeting, we felt that there was enough common ground to start a project. It took over a year to set everything up: In 2013, we received start-up funding from the DFG, and our first book came out in 2014. That was an exciting time, and we were happy to be supported by a lot of colleagues right from the beginning. Stefan has amazing technical and design abilities, and he was persuaded by key aspects of my strategic vision. We had hoped that our publishing imprint would be a big success, but in hindsight, the success was bigger than we could have realistically expected. To a large extent, this was of course because we found exactly the right person to manage our day-to-day operations 🙂 On the other hand, it was a bit of a disappointment that our model was not copied more often by others. Open-access publication is becoming more and more common, but most of it is top-down, with the big commercial publishers controlling most aspects. So Language Science Press is still a very special enterprise.
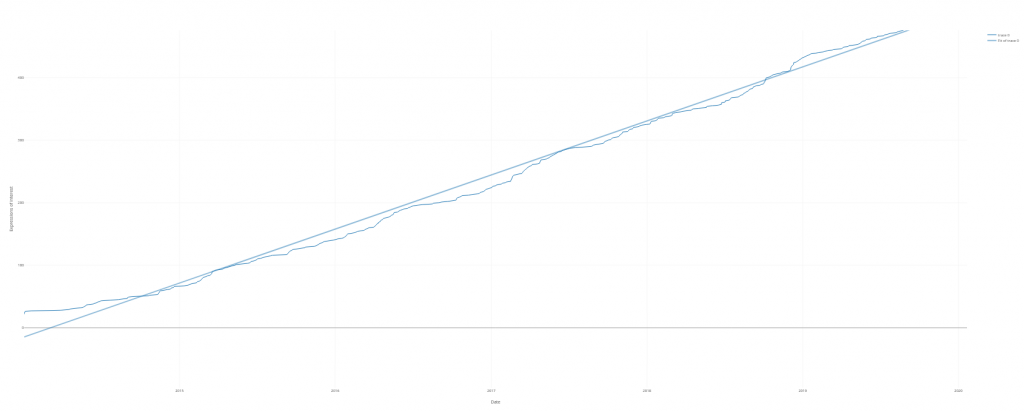
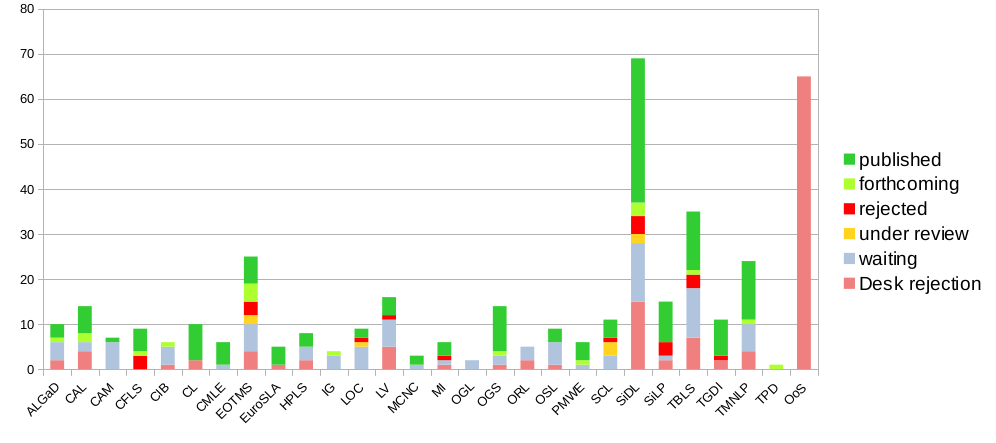
As of today, your series Studies in Diversity Linguistics has 32 published books and 105 expressions of interest. How do you cope with that interest and demand?
That’s indeed a good question – and sometimes I don’t (some authors will know what I mean, because I don’t always reply super fast). Due to my position at a prestigious Max Planck Institute, my name is very well known, so this generates trust and interest in the series that I started, I think. Ideally, the work would be distributed over more shoulders. On the other hand, I have more time than most of my colleagues as my position does not involve teaching, so I feel a particular obligation to invest my time in service to the community. For the task of reviewing submitted books, I have developed a somewhat novel approach, which has helped especially for voluminous grammars: Instead of asking a single colleague to review a 600-page work, I ask 24 colleagues to review a 50-page chapter (so that in the end, every chapter is read by two colleagues). This means a lot of correspondence, but as I do it in the traditional way (not via an automated system), this is also quite nice at a personal level.
The median time from submission to decision is now 97 days (-1). The median time from submission to publication was 257 days (-14).
The acceptance rate (counting desk rejections) is 53.75% (+1.51) over all series. Only considering submissions where the proposal had been previously approved, the acceptance rate is 88.71% (+1.75).
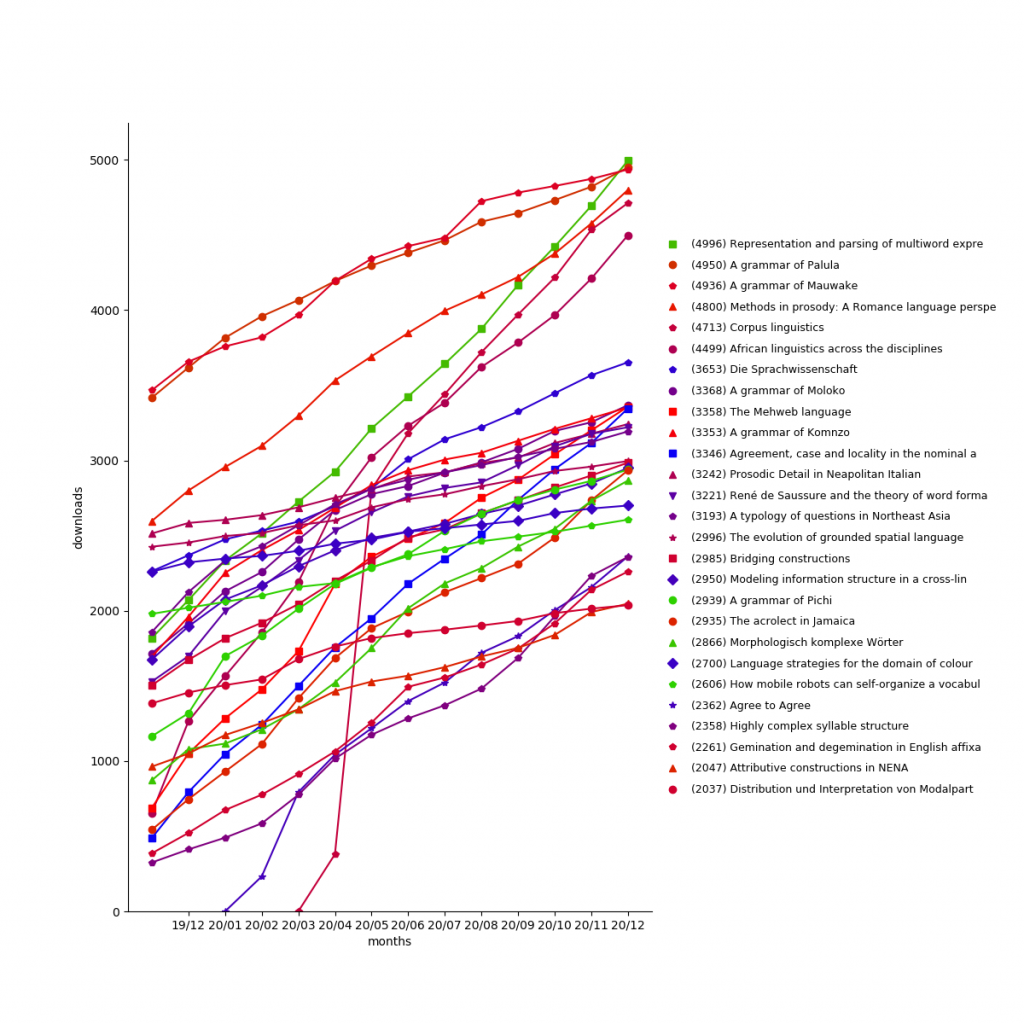
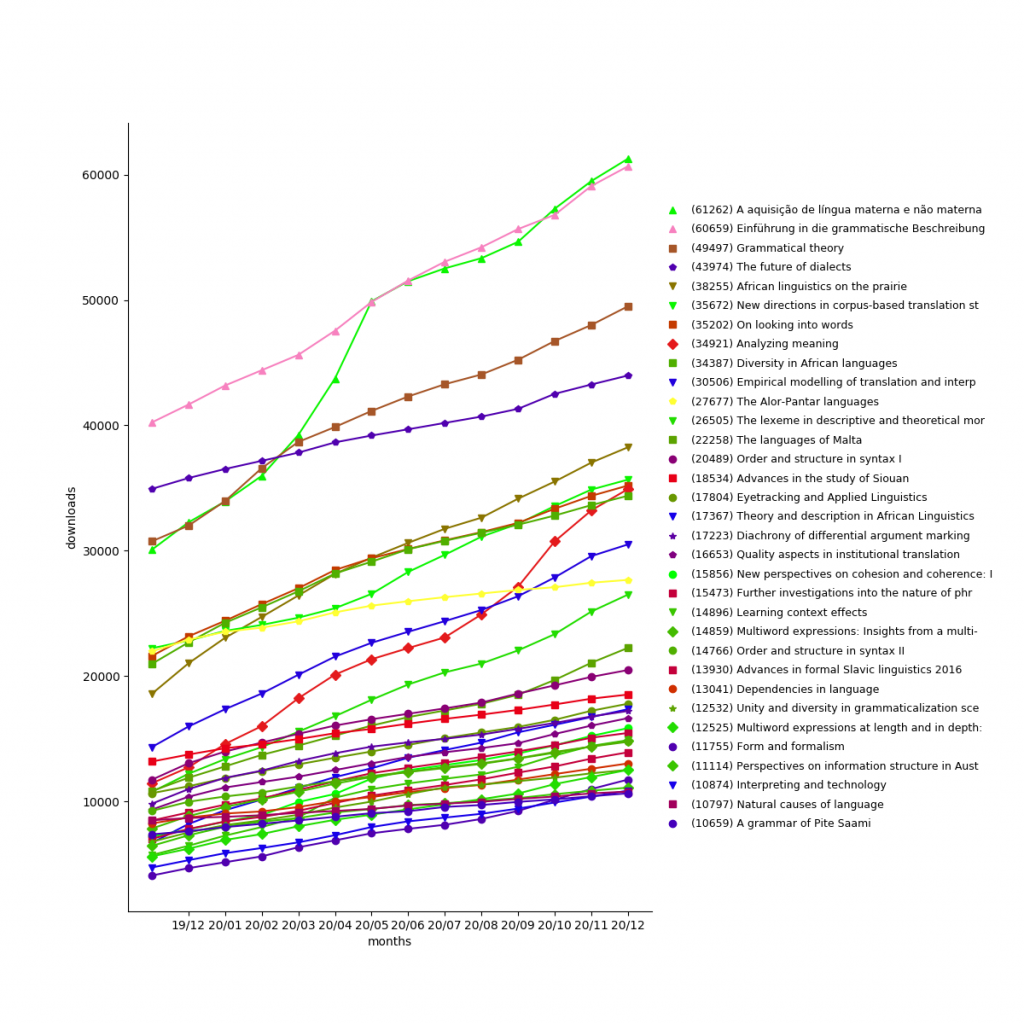
Downloads
In 2020, LangSci pdfs were downloaded 469,848 times (+106,865 compared to 362,983 in 2018), for a grand total of 1,149,905. This excludes downloads by search engine robots.
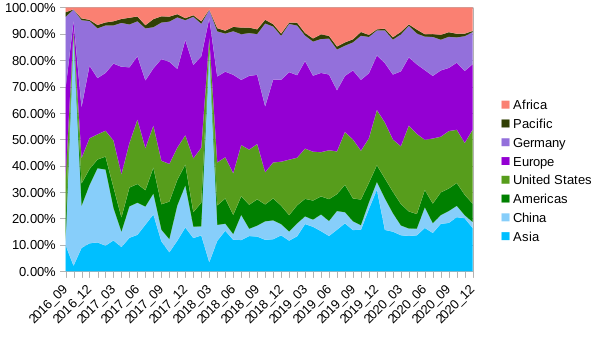
LangSci books have been accessed from 136 different countries and territories. The following chart gives a breakdown of the percentages of downloads per month for different areas of the world.
Proportion of downloads from different world regions. Africa and the Americas are increasing their share.
Community involvement
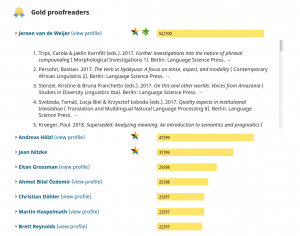
Language Science Press is a community enterprise. We rely on the community for authoring and reviewing, but also for typesetting and proofreading. Across all published books, 236 linguists from all over the world have participated in proofreading. The most prolific proofreader is Jeroen van de Weijer, who has proofread chapters of 70 books. There are currently 453 proofreaders registered with Language Science Press (+53).
For our 27 series, we are happy to be able to rely on 408 members in editorial boards from 49 different countries on 6 continents.
Paperhive
Of the books published in 2020, 27 went through proofreading on Paperhive. A total of 18,372 comments were left, for an average of 680 (median: 675). The book with the most comments was “Multi-verb constructions in Eastern Indonesia” (1355). The total number of books which have completed proofreading on Paperhive is 103. Total number of comments over all books is 73,158 (mean: 710, median: 647)
CO₂
Due to the pandemic, we only travelled to one conference, 576km return. This was by train and emitted 0g CO₂. We are still unable to quantify our electricity and heating CO₂ footprint.
Finances
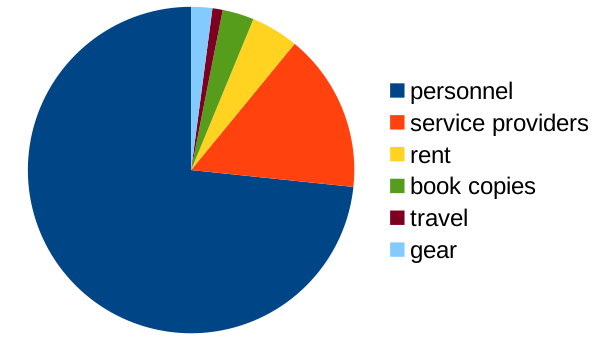
We had a revenue of 113,756.15 € (-18,951.76) in 2019 and expenditures of -120,676.92 € (+675.17). The main cost items are personnel (89,772.25 €), service providers (19,245.13 €), rent (5,752.10 €), book copies (3,825.57€), travel (1,244.21€), and gear (2,557.79€). A total of five different employees of four different nationalities have received a salary from Language Science Press (none of them full time, and only two of them 12 months).
Cost items for the year 2020. Personnel is about 75%.
Given that our expenditures remained stable at 120k, as did the number of books we published (30), we again arrive at a very round figure of 4000€ to produce one book (See here for an overview of costs elsewhere, ranging from 8k to 18k€).
Back in 2017, we wrote a blog post on fluid publication. This explained the development of a book by the author together with the readership, reusing techniques well-known from software development.
The author 1) starts with a draft version, collects feedback from colleagues, and then the stages of 2) (open) review, 3) acceptance, 4) community proofreading and finally 5) publication of the first edition follow. A history of the different versions is kept on GitHub. GitHub also provides functionalities to manage lists of open issues which still have to be addressed before the next stage can be initiated.
As detailed in various posts on this blog, we use PaperHive for community proofreading. Today, we can showcase docLoop, which allows us to transform the community comments into todo lists on GitHub, closing the loop from author to reader and back from the reader to the author.
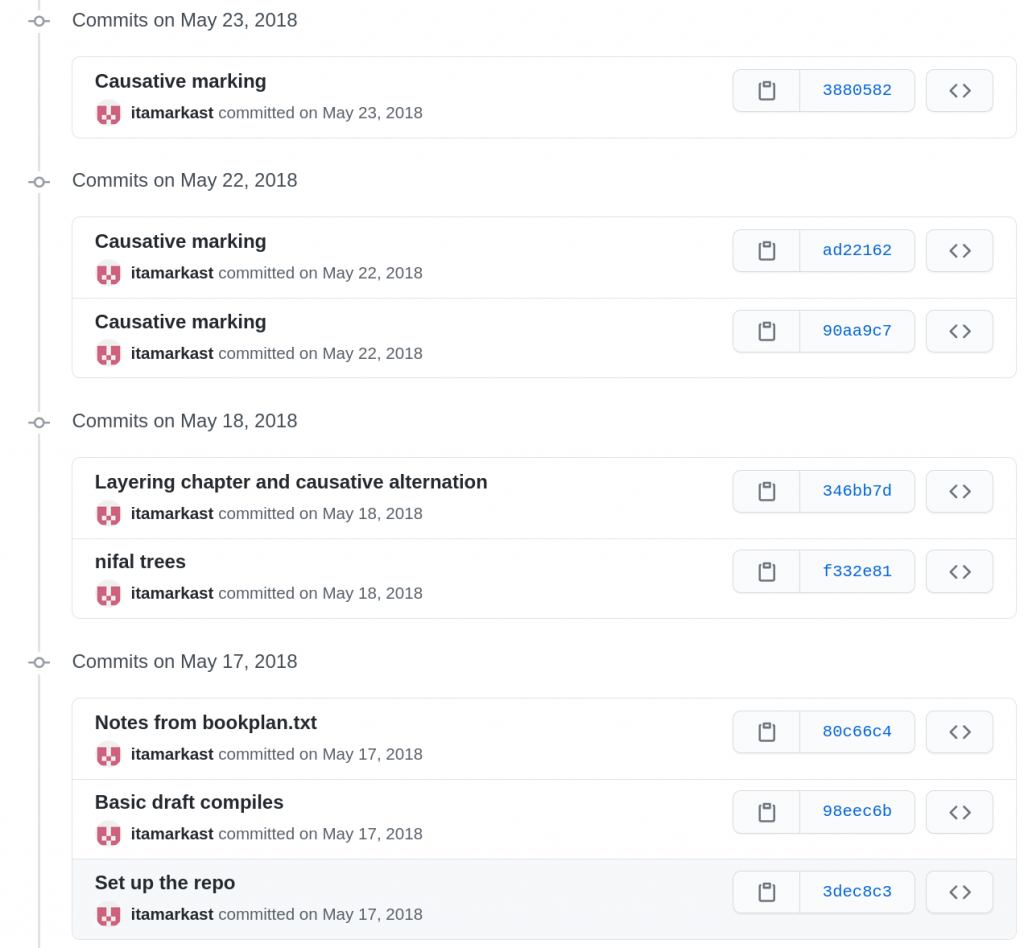
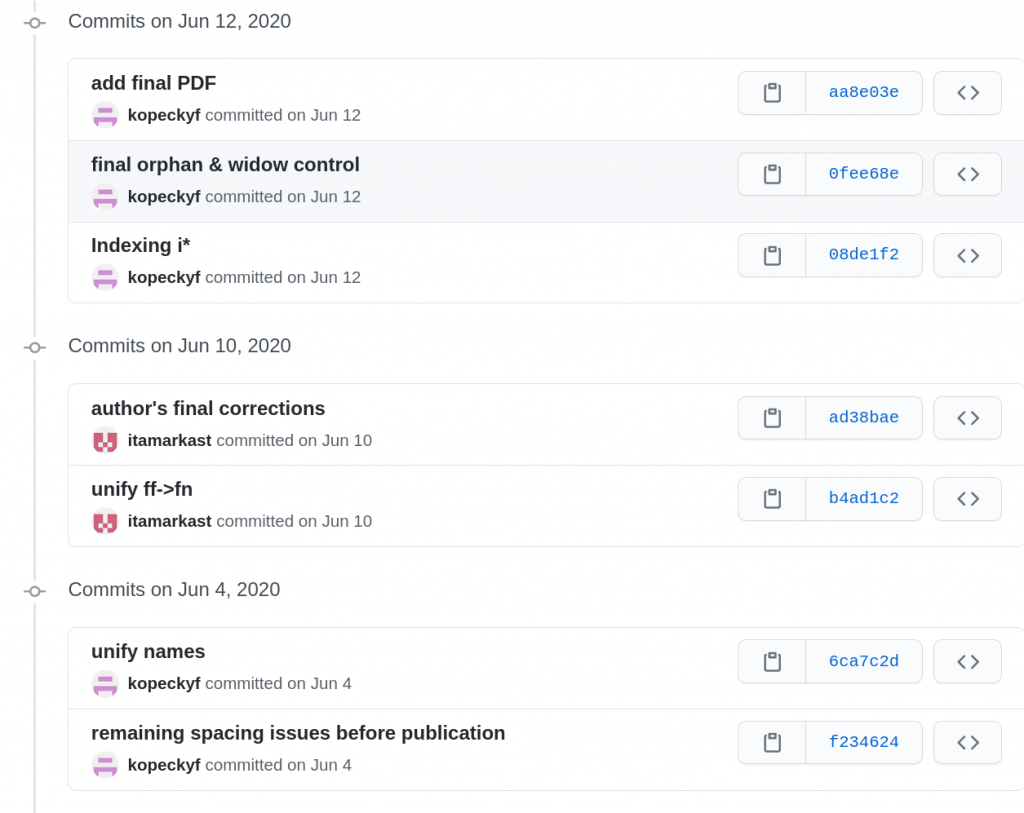
Let’s look at an example, Voice at the interfaces: The syntax, semantics, and morphology of the Hebrew verb by Itamar Kastner. We can see the progress of this book on its GitHub page. The book was started in June 2018 and finalised in June 2020. Between the setup of the project and the publication, we count 259 different versions. Next to the author itamarkast, who provided 227 improved versions, kopeckyf and Glottotopia from the LangSci team provided 24 and 3 commits, respectively.
The first commit of this repository, on May 17, 2018
The last commit to this repository, on June 12, 2020.
Jeroen, you started community proofreading in June 2017 and have participated in 52 published books up to now. You are #1 in the LangSci Hall of Fame.
What were your motivations to sign up as a community proofreader? How did you hear about this possibility?
I think I saw a book in the series and browsed the website–partly out of linguistic interest, and partly as a supporter of open access. I have been editing books and journals for many years, so I like this kind of activity and have gotten a bit of an eye for things that may go wrong in linguistic texts. It’s very nice if you can, once in a while, prevent an author from making a mistake where they forgot a not (or a crucial comma, haha) – it’s nice to make things better, even if it’s only a little.
How do you like the process so far? What have your experiences been?
I like the process. “Crowd-reading” like this is a good idea. Sometimes I read comments by other proofreaders, and note that they do things differently than me. Apparently that’s not a problem, and further streamlining is probably neither necessary nor really warranted (maybe references could still be automatically improved, or American vs British vs Australian English spelling). It’s up to the author, of course, to see what they do with the corrections and comments, and it’s nice to think that a text could still be further improved at some point in the future. Perhaps we can have an evaluation some time.
Could you tell us how you go about a new chapter when you receive it?
I dive right in. I always read the acknowledgements (who doesn’t?), but then I turn to the assigned chapter, start at page 1 and don’t usually stop until I’m at the end. Because of the time difference I often read early in the morning, when I can work for a few hours at a stretch.