Back in 2017, we wrote a blog post on fluid publication. This explained the development of a book by the author together with the readership, reusing techniques well-known from software development.
The author 1) starts with a draft version, collects feedback from colleagues, and then the stages of 2) (open) review, 3) acceptance, 4) community proofreading and finally 5) publication of the first edition follow. A history of the different versions is kept on GitHub. GitHub also provides functionalities to manage lists of open issues which still have to be addressed before the next stage can be initiated.
As detailed in various posts on this blog, we use PaperHive for community proofreading. Today, we can showcase docLoop, which allows us to transform the community comments into todo lists on GitHub, closing the loop from author to reader and back from the reader to the author.
Let’s look at an example, Voice at the interfaces: The syntax, semantics, and morphology of the Hebrew verb by Itamar Kastner. We can see the progress of this book on its GitHub page. The book was started in June 2018 and finalised in June 2020. Between the setup of the project and the publication, we count 259 different versions. Next to the author itamarkast, who provided 227 improved versions, kopeckyf and Glottotopia from the LangSci team provided 24 and 3 commits, respectively.
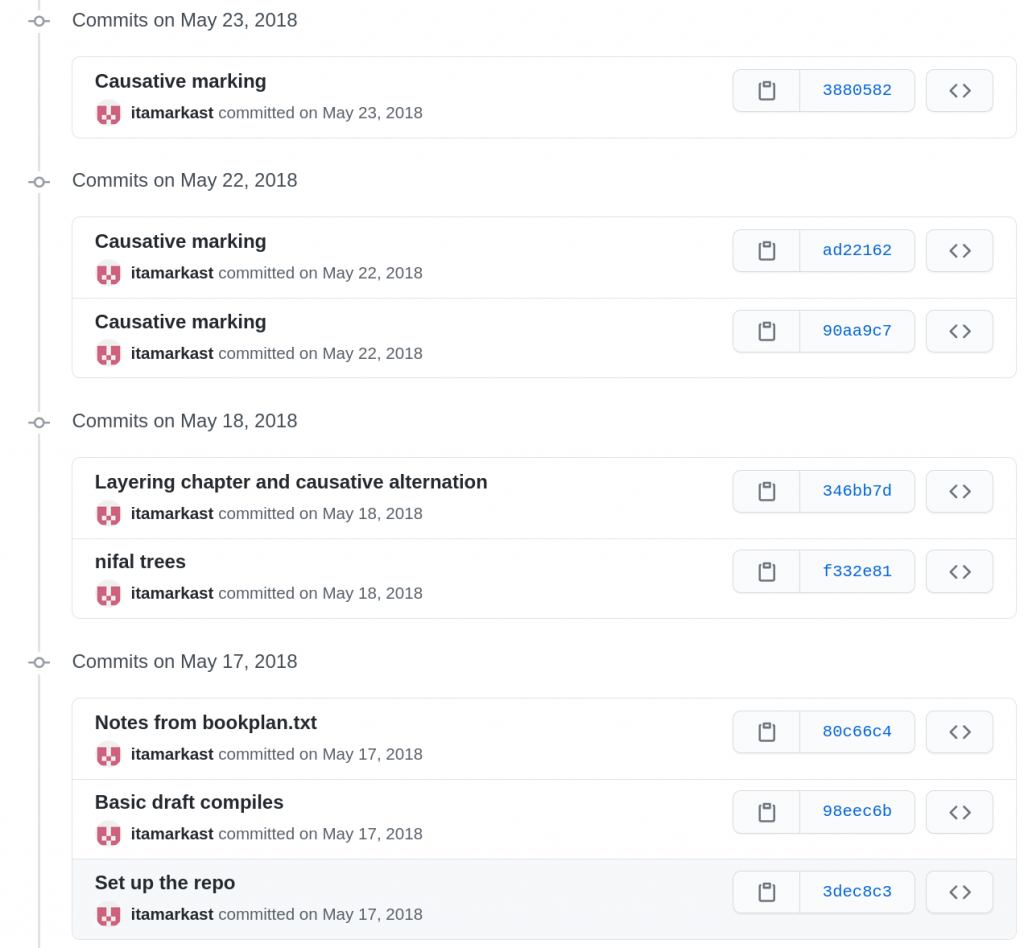
The first commit of this repository, on May 17, 2018 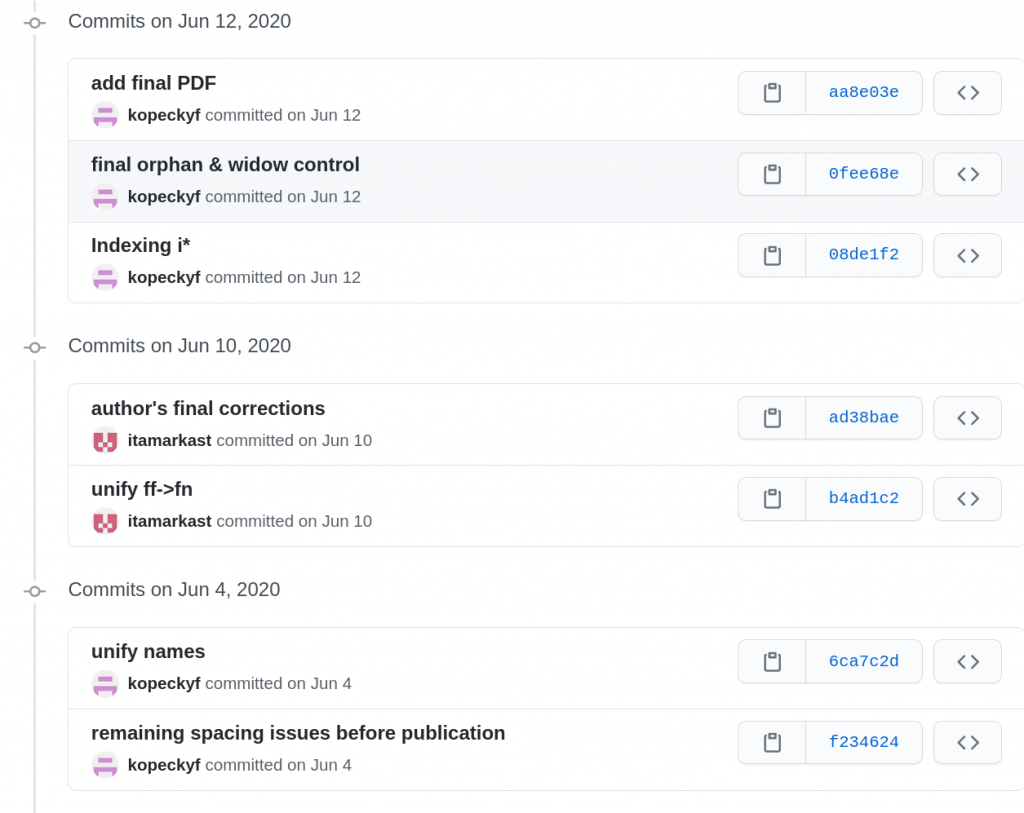
The last commit to this repository, on June 12, 2020.