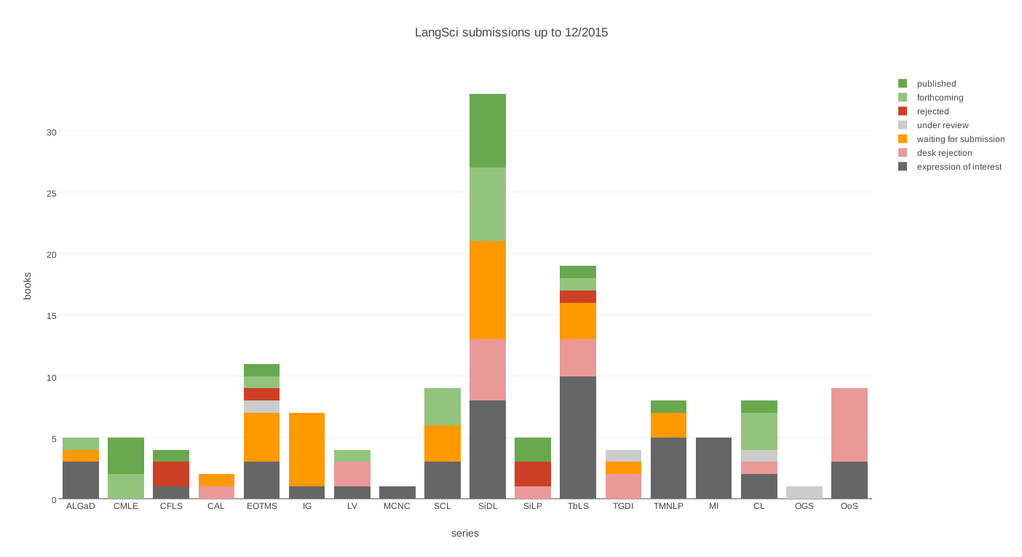
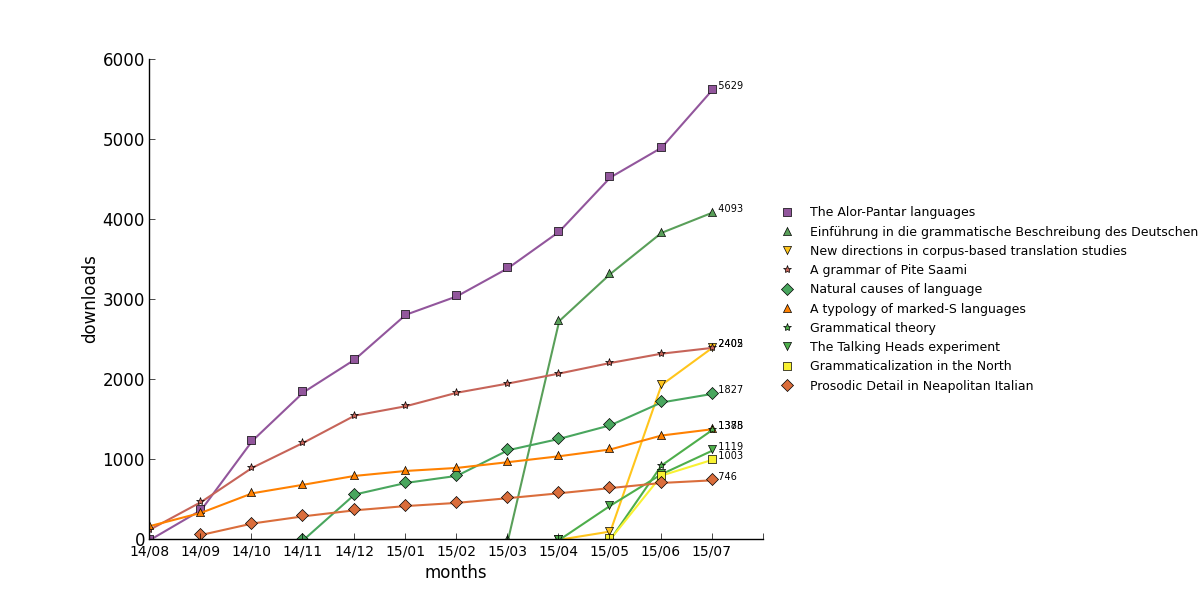
Publishing does not come for free. There are a number of obvious costs, such as ink, paper or computer storage, and a couple of not-so-obvious costs, such as the time needed to set up a book for print-on-demand or the creation of user manuals and screencasts.
These costs have to be counterbalanced by revenue. Traditionally, publishers recoup their costs via the margin of their book sales. In an open access paradigm with a smaller print run, this is less straightforward.
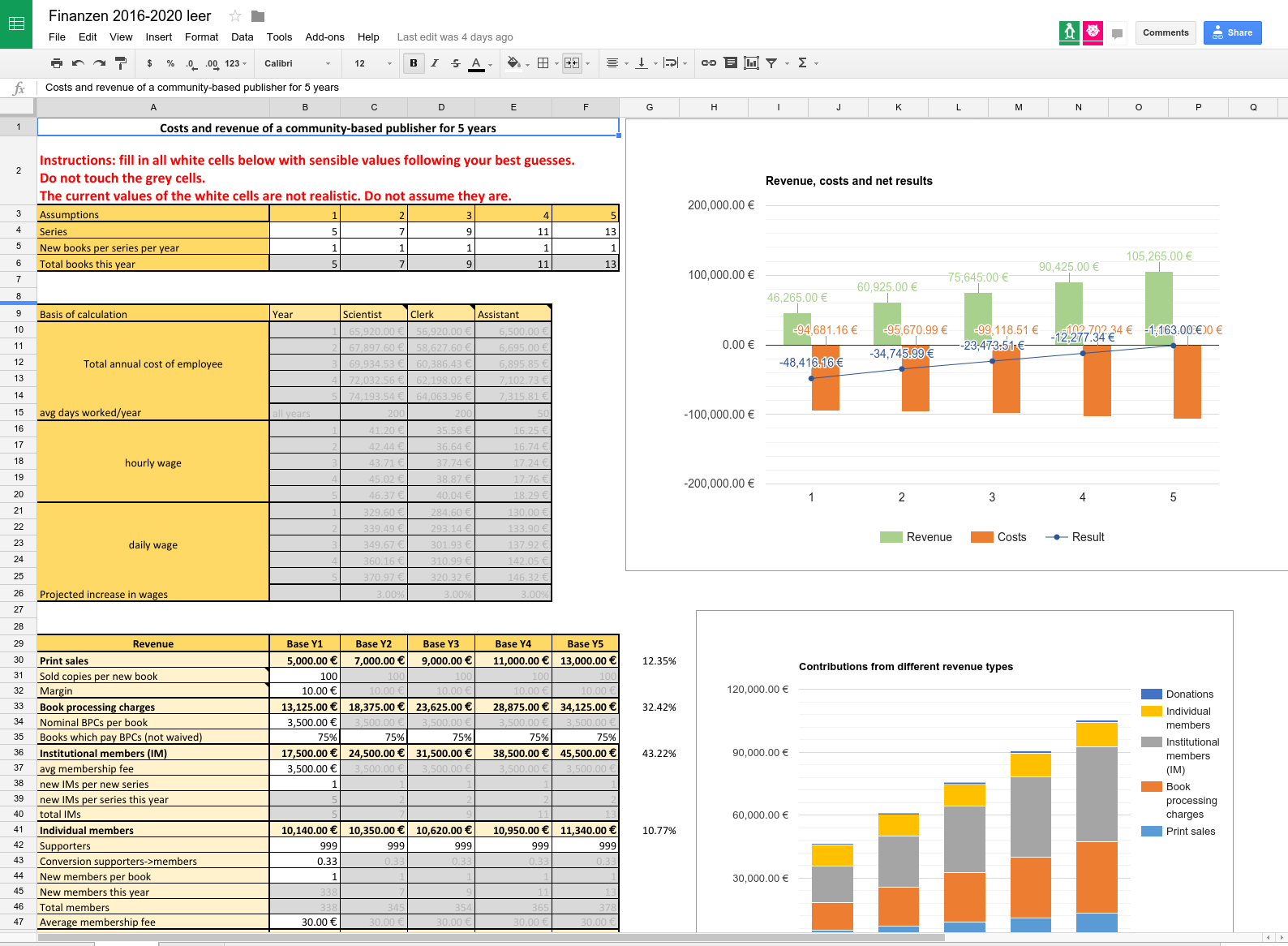 We have created an interactive spreadsheet where you can assume the role of press editor and see how you can make the ends meet. You can download the spreadsheet or use the online version (you will have to copy the online version to be able to edit). In what follows, I will detail the different sources of revenues, roles, and expenditures. You can use the spreadsheet right away, but it might be worthwhile to read what the individual categories stand for.
We have created an interactive spreadsheet where you can assume the role of press editor and see how you can make the ends meet. You can download the spreadsheet or use the online version (you will have to copy the online version to be able to edit). In what follows, I will detail the different sources of revenues, roles, and expenditures. You can use the spreadsheet right away, but it might be worthwhile to read what the individual categories stand for.